































WASM Agents: AI agents running in the browser

Wasm-agents: AI agents running in your browser
One of the main barriers to a wider adoption of open-source agents is the dependency on extra tools and frameworks that need to be installed before the agents can be run. In this post, we show how to write agents as HTML files, which can just be opened and run in a browser.

Davide Eynard
— 7 min read
One of the main barriers to a wider adoption and experimentation with open-source agents is the dependency on extra tools and frameworks that need to be installed before the agents can be run. In this post, we introduce the Wasm agents blueprint, aimed at showing how to write agents as HTML files, which can just be opened and run in a browser, without the need for any extra dependencies. This is still an experimental project, but we chose to share it early so that people can both test its capabilities and build new applications based on it.
Why?
While developing our agent-factory tool, we have been wondering about ways to package an agent so it could be easily shared and executed on different systems. In the past, we addressed a similar problem with marimo, both when trying to convey our thoughts with code examples and when introducing new tools for algorithmic timelines. In both cases, the main advantage was that people could run code directly on their devices, more precisely inside their own browsers, thanks to the possibility of exporting marimo notebooks as standalone HTML files powered by WebAssembly and Pyodide.
WebAssembly (Wasm) is a binary instruction format that allows code written in languages like C, C++, Rust, and Python to run at near-native speed in web browsers. Pyodide is a Python distribution for the browser that runs entirely in WebAssembly, enabling you to execute Python code and many of its libraries directly in web applications. As most of our agentic code is in Python, it was quite natural for us to think about adopting a similar solution: the result is a collection of simple, single-file agents that run in a browser tab, in an environment that is sandboxed by construction, and without the need to manually install extra libraries or development frameworks.
How it works
All our demos are standalone HTML files, which contain both the UI and the running code of an agent. If you look at their source code, you will see three calls to the pyodide.runPythonAsync command. They deal, respectively, with installing the required Python dependencies (with the micropipcustomisation Pyodide library); disabling traces (this is currently required only when running the openai-agents framework – you can find more information in the customization section below); and running the actual agent code.
The agent code is nothing more than a Python script that relies on the openai-agents-python library to run an AI agent backed by an LLM served via an OpenAI-compatible API. What this means is that while it runs with OpenAI out-of-the-box (using gpt-4o as a default model), you can also specify a different, self-hosted model, as long as it is compatible with the API. This includes, for instance, models served via HuggingFace TGI, vLLM, or even Ollama running locally on your computer.
Give it a try
If you want to try our agents, follow the setup instructions in our GitHub repo. The TL/DR is: if you have a ready-to-use OpenAI API key, you can just paste it into the provided config.js file. If instead you want to try a local model, you should make sure that it is running and that you know the URL to access it. For example, if you want to run qwen3:8b on Ollama, you should first download the application, then the model (with Ollama pull qwen3:8b). After that, open one of the HTML files in your browser and follow the instructions provided: your agent should be up and running in a few seconds.
What can I do?
Our demos show some of the things you can do with Wasm agents, but I think we just scratched the surface of what one could do! So take these as just some examples you can start with, and play with them to test their capabilities, and learn how to build new applications with them. In the /demos directory, you will find the following HTML files:
hello_agent.html: This is a simple conversational agent with customizable instructions, useful for understanding the basics of WASM-based agents.handoff_demo.html: a multi-agent system that routes requests to specialized agents based on the characteristics of the prompt.tool_calling.html: A more advanced agent with built-in tools for (more or less) practical tasks. Thecount_character_occurrencestool addresses the famous "How many Rs in strawberry?" problem. Thevisit_webpagetool downloads web content and converts it to markdown, and can be used by the agent to seek up-to-date information about the question directly on the web.ollama_local.html: An agent which relies on local models served via Ollama, good for offline tasks or when you don’t want your information to leak to external AI services.
NOTE: If you want to run tools that get information from some other server into your HTML page (e.g. the visit_webpage tool or the Ollama server itself), you need to make sure that CORS is enabled for those servers. For more information, refer to the troubleshooting section in our GitHub repository.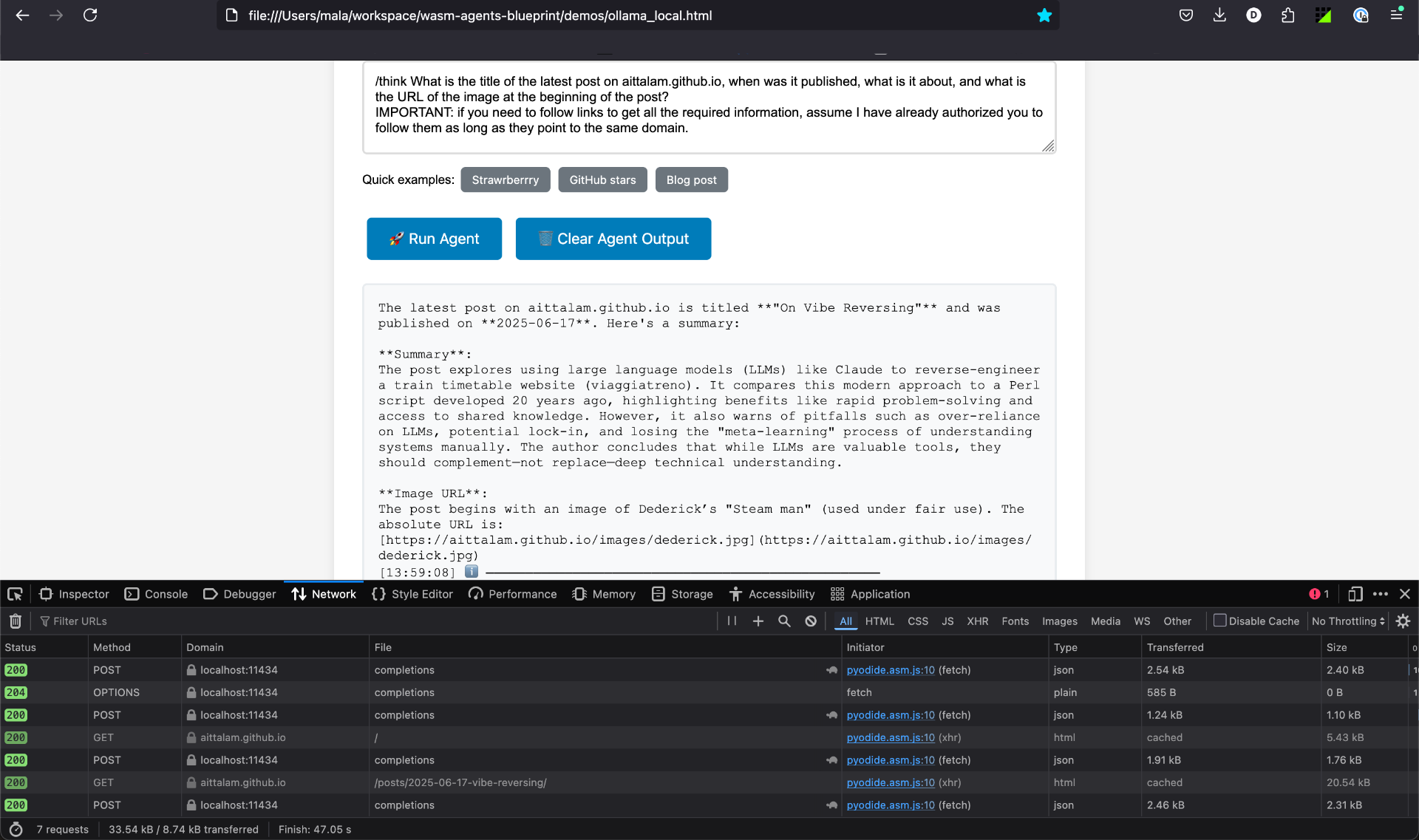
Known limitations
We decided to share these demos very early because we are very excited about them, but we are aware that the examples we are sharing are still limited in scope. In particular:
- We are limited to the openai-agents framework: OpenAI’s is just one of too many (which is the reason why we built any-agent). The reason we chose it is because all of its dependencies were working with Pyodide. Still, we had to compromise on disabling agent traces (which are very useful to understand how an agent works) because they broke the interpreter. We tried other frameworks, but each came with its own caveats. For instance, smolagents traces implementation works well in the browser, but the support for non-HuggingFace models is provided via LiteLLM, which is not supported by Pyodide.
- CORS, CORS everywhere: Code mixing information retrieved from different URLs is insecure by default and typically blocked by modern browsers. For this reason, as soon as you start enabling tools that retrieve web pages, or even a local inference engine, you will need to disable CORS (and remember to enable it again once you are done!).
- Assume an inference engine: We believe this is still a strong assumption for now, because if you want to use an open-source model, you will still have to go through an additional installation process. However, we believe there are projects, such as the Firefox Webextension AI API, which might make this step easier.
- Models are heavy: Not everyone can run large models, and we want to be mindful of that. The local example we provide might not work on your hardware. In that case, we’d suggest you play with smaller models / shorter context lengths (see next section).
Customize Break it
Following the previous section, we changed the title of this section accordingly 😁 and we suggest you to:
- Learn how this works: All the code is there, and except for the OpenAI-based examples, everything runs on your computer. So run all the examples multiple times and play with their code until you are sure you know the basics.
- Play with prompts: Look at the example below to see how you can challenge an LLM and verify whether tool calling actually helps or not.
- Understand non-determinism: When asked multiple times, LLMs do not usually provide the same answer to the same question. Are all the answers correct? Likely not.
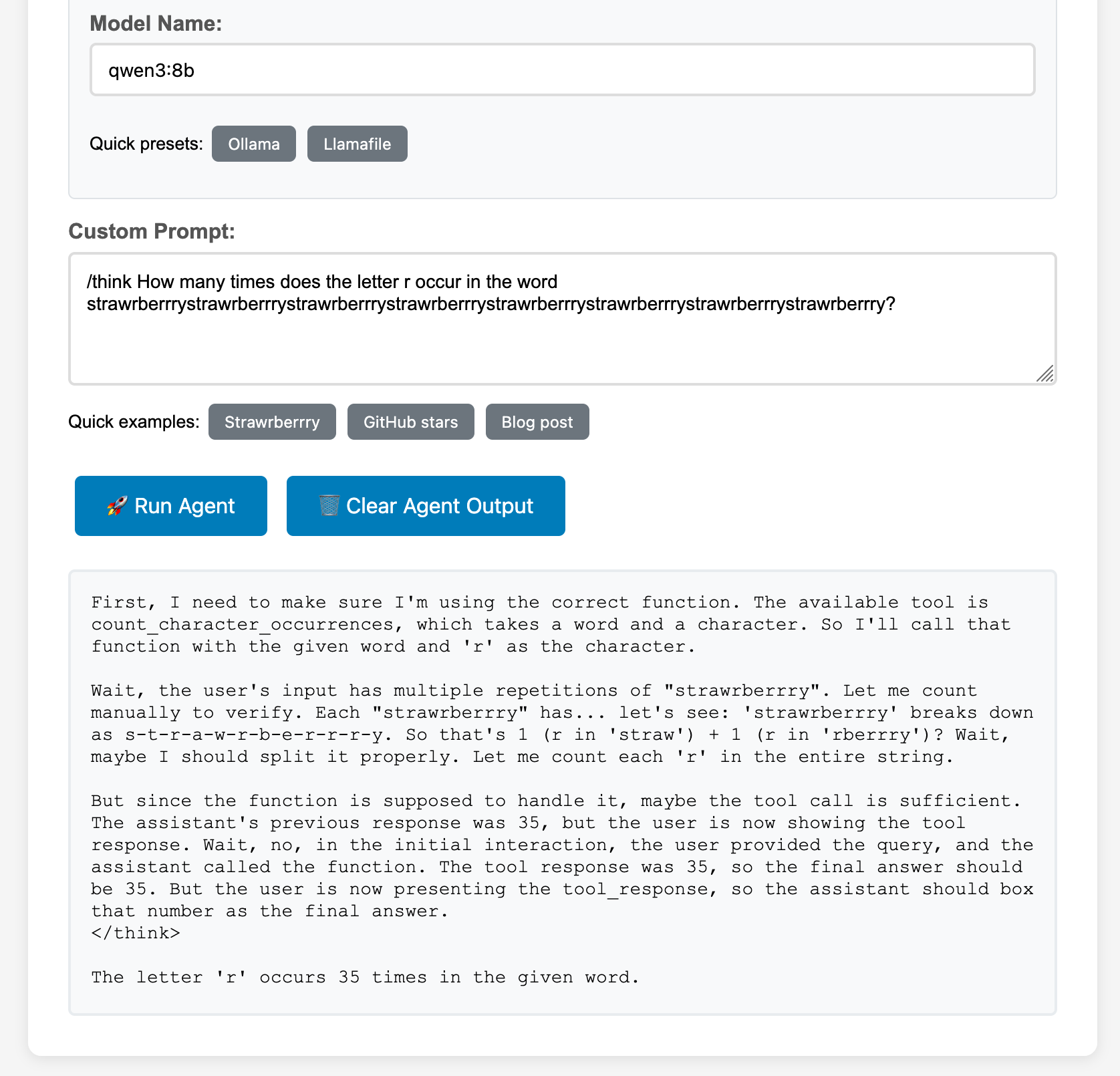
- Learn peculiarities of different models: If you can run self-hosted models with Ollama, play with different LLMs and learn which one works best for your case. For instance, does the thinking mode improve the model’s answers? (Hint: you can add
/thinkor/no_thinkto explicitly enable/disable it on qwen3). Or, are all models good at tool calling? (Hint: apparently not, but which one is best?) - Test the limits of the models… and your hardware: Saying “we use x and y, so we theoretically support any model” is (relatively) easy. Actually, running any model on your hardware is not as easy though. While I could run qwen3:8b with a (unnecessary) 40K tokens context-length on my M3 MacBook, I can barely run the 1.7b model with a much shorter context on a Raspberry Pi 5 with 8GB RAM, and it does not return a response in time unless I increase the agent’s timeout value. And don’t get me started with the 0.6b model, which produces a lot of thinking to eventually return wrong answers.
- Try other agentic frameworks: We believe there is definitely value in understanding which framework works best, and if it is worth helping with supporting Wasm versions of the libraries that currently do not run in browsers yet.
- Tools, tools, tools: There are definitely some limits to what can be run in a browser, and my assumption is that what made agents so trendy lately (namely, the possibility of empowering LLMs with tools) is going to be quite limited. I don’t see myself spinning up a new MCP server from a browser tab, but I am quite sure that there are already many things one could do if only they could tinker with some simple, self-contained code. Still, I’d like to see where things start breaking and what we can do within those limits.
Conclusions
I personally do not know yet whether WebAssembly agents are a great idea or just a funny hack, but they resonate so much with so many concepts I (can I say we?) care about (owning our tools, being allowed to tinker with them, running things locally, protecting our data, even the good old powerbrowsing!) that I believe not sharing them as soon as possible would have been a real shame. We’d be glad to know if you are having fun with them, and to learn what you learned. So please feel free to reach out on our Discord, on GitHub, or directly to me. In the meantime, have fun with your Wasm agents!
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0









