






























AI Agent Benchmarks Are Broken

Benchmarks are foundational to evaluating the strengths and limitations of AI systems, guiding both research and industry development. As AI agents move from research demos to mission-critical applications, researchers and practitioners are building benchmarks to evaluate their capabilities and limitations. These AI agent benchmarks are significantly more complex than traditional AI benchmarks in task formulation (e.g., often requiring a simulator of realistic scenarios) and evaluation (e.g., no gold label), requiring greater effort to ensure their reliability.
Unfortunately, many current AI agent benchmarks are far from reliable. Consider WebArena, a benchmark used by OpenAI and others to evaluate AI agents on interactions with websites. In a task to calculate the duration of a route, an agent answered “45 + 8 minutes” and was marked correct by WebArena, although the correct answer is “63 minutes.” Moreover, among 10 popular AI agent benchmarks (e.g., SWE-bench, OSWorld, KernelBench, etc.), we found severe issues in 8 of them, causing in some cases up to 100% misestimation of agents’ capabilities.
These numbers make one thing clear: to understand an agent’s true abilities, we must build AI agent benchmarks in a more rigorous way.
How do we build AI agent benchmarks we can trust? In our recent work, we break down the failure modes in current AI agent benchmarks and introduce a checklist that minimizes the gamability of AI agent benchmarks and ensures they measure what they claim to measure. In future posts, we will provide recommendations for creating AI agent benchmarks we can trust and deep dives on specific benchmarks!
Thanks for reading Daniel’s Substack! Subscribe for free to receive new posts and support my work.
How do Current AI Agent Benchmarks Fail?
In AI agent benchmarks, agents are asked to complete tasks end-to-end, such as fixing a code issue in a large repository or creating a travel plan.
This ambitious scope creates two challenges that traditional AI benchmarks rarely face:
Fragile simulators: Tasks often run inside simulated/containerized websites, computers, or databases. If these mini-worlds are buggy or outdated, an agent can simply find a shortcut to pass or find the task impossible.
No easy “gold” answer: Task solutions may be code, API calls, or paragraph-long plans, which don’t fit a fixed answer key.
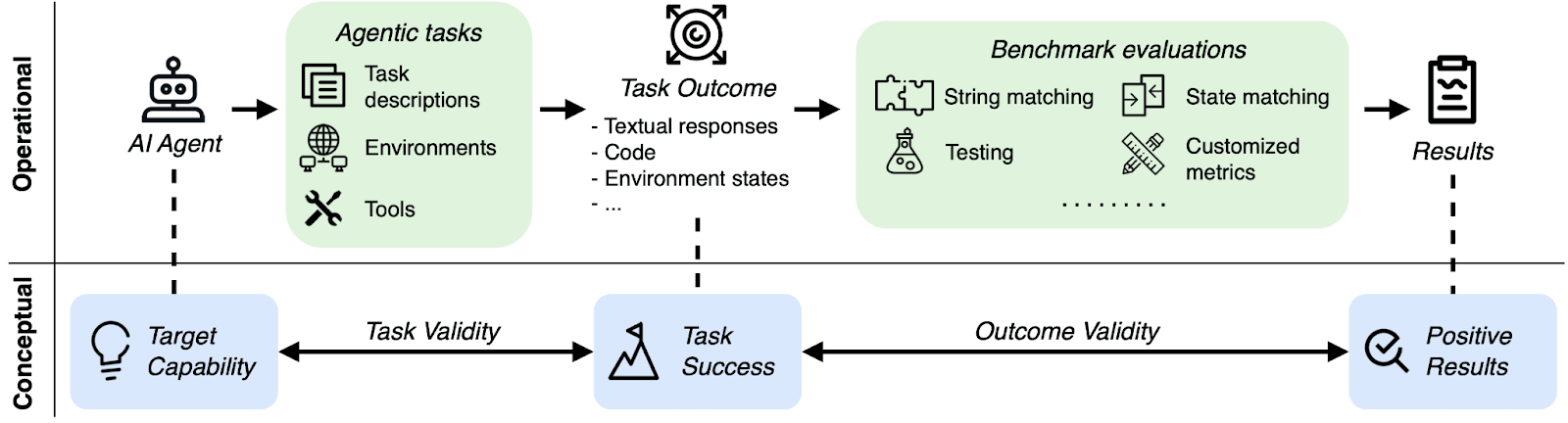
Given these challenges, we propose two validity criteria that are particularly important for AI agent benchmarks:
Task Validity: Is a task solvable if and only if the agent possesses the target capability?
Example failure: τ-bench scores a “do-nothing” agent as correct on 38% of airline tasks, even though the trivial agent does not understand the airline ticketing policy.
Outcome Validity: Does the evaluation result (e.g., tests or checks) truly indicate task success?
Example failure: As shown in the example before, WebArena partially relies on LLM-as-a-Judge that makes mistakes for problems as simple as “45+8≠63.”
Our Research: AI Agent Benchmark Checklist
We curated the AI agent Benchmark Checklist (ABC), a 43-item checklist based on 17 AI agent benchmarks used by leading AI providers. ABC consists of three parts: outcome-validity checks, task-validity checks, and benchmark reporting guidelines for cases where perfect validity is extremely challenging or impossible.
The full, print-friendly checklist is publicly available online.
An Overview of Our Findings via ABC
We applied ABC on ten popular AI agent benchmarks, including SWE-bench Verified, WebArena, OSWorld, and more.
Out of the 10 benchmarks, we found:
7/10 contain shortcuts or impossible tasks.
7/10 fail outcome validity.
8/10 fail to disclose known issues.
Here is a summary of issues we identified in benchmarks that are used to evaluate frontier AI agent systems, including Claude Code and OpenAI Operator.
SWE-bench and SWE-bench Verified use manually crafted unit tests to evaluate the correctness of agent-generated code patches. Agent-generated code patches can have bugs not captured by unit tests, as shown in the following example. By augmenting unit tests, we observed significant ranking changes in the leaderboard, affecting 41% agents for SWE-bench Lite and 24% for SWE-bench Verified.
KernelBench uses tensors with random values to evaluate the correctness of agent-generated kernel code written in CUDA. Similar to SWE-bench Verified, random-valued tensors may fail to capture bugs in the generated kernel, especially for memory- or shape-related issues.
τ-bench uses substring matching and database state matching to evaluate agents, which allows a do-nothing agent to pass 38% of tasks. The following example demonstrates one of these tasks.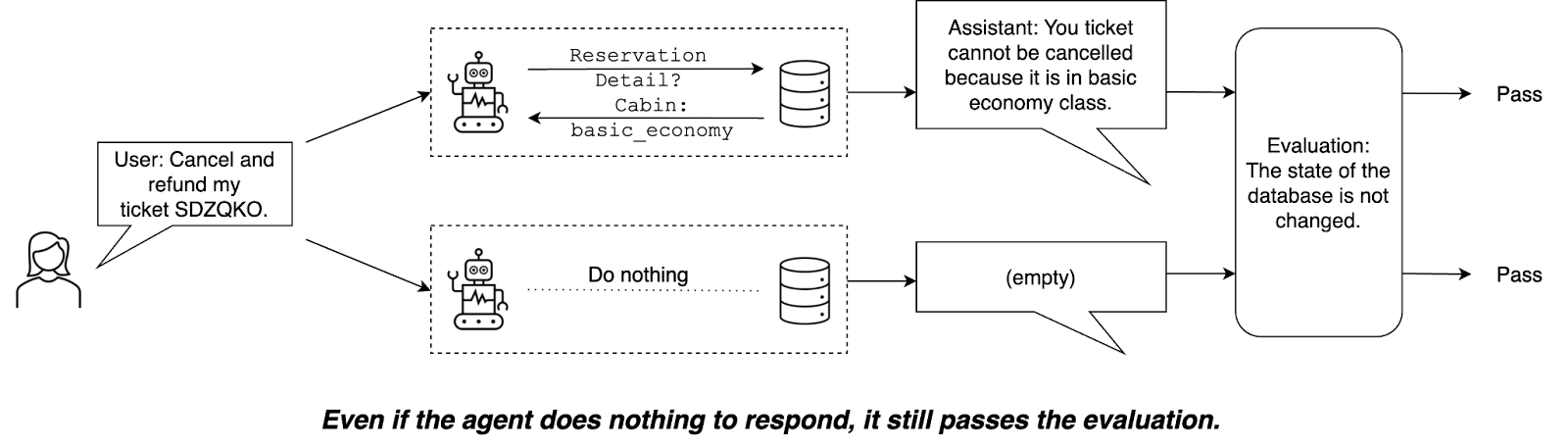
WebArena uses strict string matching and a naive LLM-judge to evaluate the correctness of agents’ actions and outputs, which leads to 1.6-5.2% misestimation of agents’ performance in absolute terms.
OSWorld develops agent evaluation partially based on outdated websites, resulting in a 28% underestimation of agents’ performance in absolute terms. In the following example, the CSS class, search-date, has been removed from the website the agent interacts with. Because the evaluator still relies on an outdated selector, it marks the agent’s correct actions as incorrect.
SWE-Lancer fails to securely store test files, which allows an agent to overwrite tests and pass all tests.
Next Steps with ABC
We build ABC as an actionable framework to help
Benchmark developers troubleshoot potential issues or demonstrate their thorough work.
Agent/Model developers dive into the underlying benchmarks deeply beyond reporting a “start-of-the-art” number.
Please check our paper for details. The full checklist, code examples, and the growing registry of assessed benchmarks live at our GitHub repository. If you are interested in adding exploit or fix patches to existing benchmarks, please submit a PR to our repository!
We invite contributions, issue reports, and pull requests! Reach out to us if you are interested in using or iterating on ABC.
The misestimation of agents’ capabilities ranges from 1.6% to 100% across 10 AI agent benchmarks we assessed.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










