






























Fast Allocations in Ruby 3.5

Many Ruby applications allocate objects. What if we could make allocating objects six times faster? We can! Read on to learn more!
Speeding up allocations in Ruby
Object allocation in Ruby 3.5 will be much faster than previous versions of Ruby. I want to start this article with benchmarks and graphs, but if you stick around I’ll also be explaining how we achieved this speedup.
For allocation benchmarks, we’ll compare types of parameters (positional and keyword) with and without YJIT enabled. We’ll also vary the number of parameters we pass to initialize so that we can see how performance changes as the number of parameters increases.
The full benchmark code can be found expanded below, but it’s basically as follows:
class Foo
# Measure performance as parameters increase
def initialize(a1, a2, aN)
end
end
def test
i = 0
while i < 5_000_000
Foo.new(1, 2, N)
Foo.new(1, 2, N)
Foo.new(1, 2, N)
Foo.new(1, 2, N)
Foo.new(1, 2, N)
i += 1
end
end
test
Full Benchmark Code
Positional parameters benchmark:
N = (ARGV[0] || 0).to_i
class Foo
class_eval <<-eorb
def initialize(#{N.times.map { "a#{_1}" }.join(", ") })
end
eorb
end
eval <<-eorb
def test
i = 0
while i < 5_000_000
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
i += 1
end
end
eorb
test
Keyword parameters benchmark:
N = (ARGV[0] || 0).to_i
class Foo
class_eval <<-eorb
def initialize(#{N.times.map { "a#{_1}:" }.join(", ") })
end
eorb
end
eval <<-eorb
def test
i = 0
while i < 5_000_000
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
i += 1
end
end
eorb
test
We want to measure how long this script will take, but change the number and type of parameters we pass. To emphasize the cost of object allocation while minimizing the impact of loop execution, the benchmark allocates several objects per iteration.
Running the benchmark code with 0 to 8 parameters, varying parameter type and whether or not YJIT is enabled will produce the following graph:
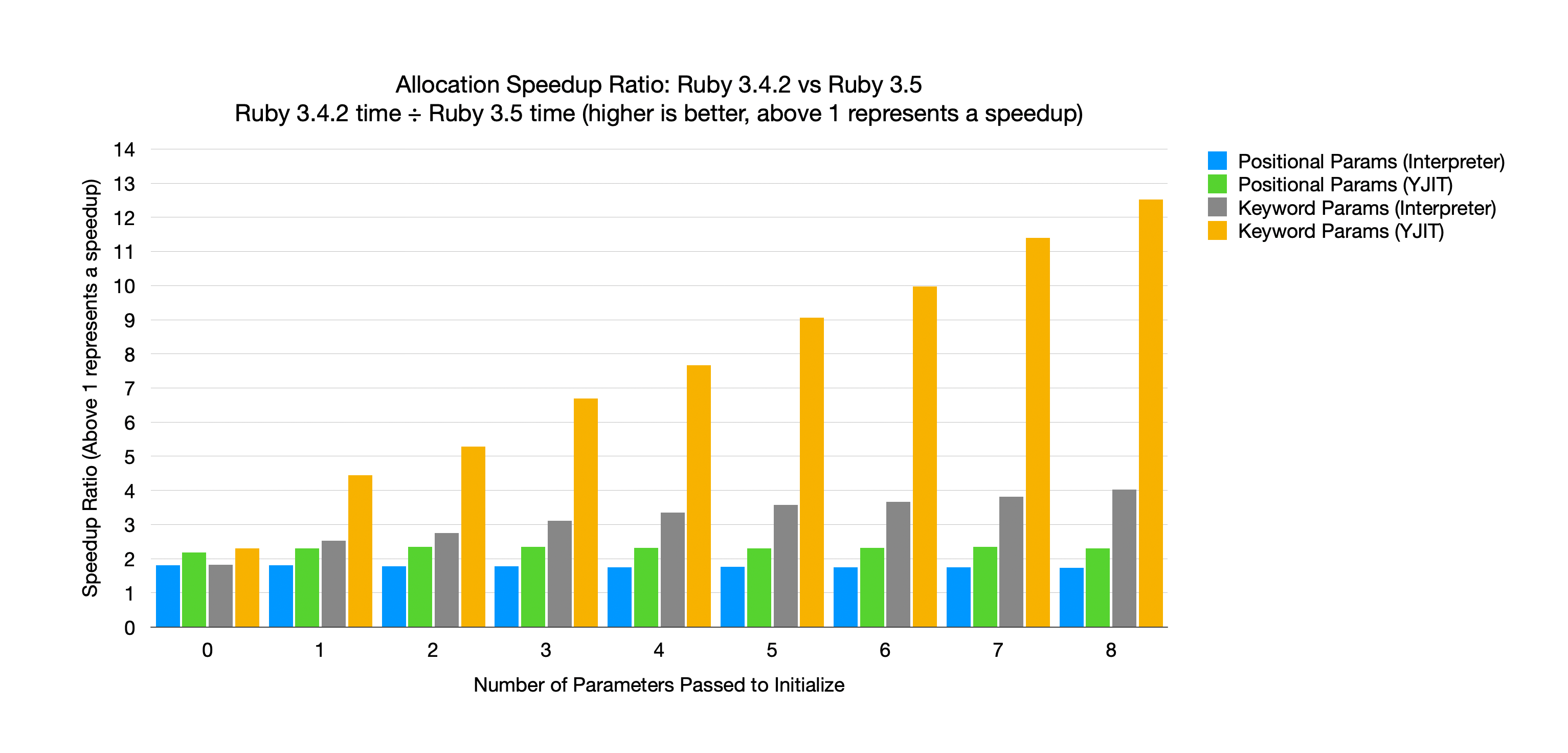
The graph illustrates the speedup ratio, calculated by dividing the time spent on Ruby 3.4.2 by that spent on Ruby 3.5. That means that any values below 1 represent a slowdown, where any values above 1 would represent a speedup. When we compare Ruby 3.5 to Ruby 3.4.2 we either disable YJIT on both versions or enable YJIT on both versions. In other words we compare Ruby 3.5 with Ruby 3.4.2 and Ruby 3.5+YJIT with Ruby 3.4.2+YJIT.
The X axis shows the number of parameters passed to initialize, and the Y axis is the speedup ratio. The blue bars are positional parameters without YJIT, the green bars are positional parameters with YJIT. The grey bars are keyword parameters without YJIT, and the yellow bars are keyword parameters with YJIT.
First, we can see that all bars are above 1, meaning that every allocation type is faster on Ruby 3.5 than on Ruby 3.4.2. Positional parameters have a constant speedup ratio regardless of the number of parameters.
Positional Parameter Comparison
For positional parameters the speedup ratio remains constant regardless of the number of parameters. Without YJIT, Ruby 3.5 is always about 1.8x faster than Ruby 3.4.2. When we enable YJIT, Ruby 3.5 is always about 2.3x faster.
Keyword Parameter Comparison
Keyword parameters are a little more interesting. For both the interpreter and YJIT, as the number of keyword parameters increases, the speedup ratio also increases. In other words, the more keyword parameters used, the more effective this change is.
With just 3 keyword parameters passed to initialize, Ruby 3.5 is 3x faster than Ruby 3.4.2, and if we enable YJIT it’s over 6.5x faster.
Bottlenecks in Class#new
I’ve been interested in speeding up allocations, and thus Class#new for a while.
But what made it slow?
Class#new is a very simple method.
All it does is allocate an instance, pass all parameters to initialize, and then return the instance.
If we were to implement Class#new in Ruby, it would look something like this:
class Class
def self.new(...)
instance = allocate
instance.initialize(...)
instance
end
end
The implementation has two main parts.
First, it allocates a bare object with allocate,
and second it calls the initialize method, forwarding all parameters new received.
So to speed up this method, we can either speed up object allocation, or speed up calling out to the initialize method.
Speeding up allocate means speeding up the garbage collector, and while there are merits to doing that, I wanted to focus on the runtime side of the equation.
That means trying to decrease the overhead of calling out to another method.
So what makes a method call slow?
Calling Ruby methods from Ruby
Ruby’s virtual machine, YARV, uses a stack as a scratch space for processing values. We can think of this stack as a really large heap allocated array. Every time we process a YARV instruction, we’ll read or write to this heap allocated array. This is also true for passing parameters between functions.
When we call a function in Ruby, the caller pushes parameters to the stack before the call is made to the callee. The callee then reads its parameters from the stack, does any processing it needs, and returns.
def add(a, b)
a + b
end
def call_add
add(1, 2)
end
For example in the above code, the caller call_add will push the arguments 1 and 2 to the stack before calling the add function.
When the add function reads its parameters in order to perform the +, it reads a and b from the stack.
The values pushed by the caller become the parameters for the callee.
You can see this in action in our recent post about Launching ZJIT.
This “calling convention” is convenient because the arguments pushed to the stack don’t need to be copied anywhere when they become the parameters to the callee.
If you examine the memory addresses for where 1 and 2 are stored, you’ll see that they are the same addresses used for the values of a and b.
Calling C methods from Ruby
Unfortunately C functions do not use the same calling convention as Ruby functions. That means when we call a C function from Ruby, or a Ruby function from C, we must convert method parameters to their respective calling convention.
In C, parameters are passed via registers or machine stack. This means that when we call a C function from Ruby, we need to copy values from the Ruby stack into registers. Or when we call a Ruby function from C, we must copy register values to the Ruby stack.
This conversion between calling conventions takes some time, so this is a place we can target for optimization.
When calling a C function from Ruby, positional parameters can be directly copied to registers.
static VALUE
foo(VALUE a, VALUE b)
{
return INT2NUM(NUM2INT(a) + NUM2INT(b));
}
# calls the `foo` C function
foo(1, 2)
In the above example, on ARM64, the parameters a and b will be in the X0 and X1 registers respectively.
When we call the foo function from Ruby, the parameters can be copied directly to the X0 and X1 registers from the Ruby stack.
Unfortunately the conversion isn’t so simple for keyword parameters. Since C doesn’t support keyword parameters, we have pass the keyword parameters as a hash to the C function. This means allocating a new hash, iterating over the parameters, and setting them in the hash.
We can see this in action with the following program when run on Ruby 3.4.2:
class Foo
def initialize(a:)
end
end
def measure_allocations
x = GC.stat(:total_allocated_objects)
yield
GC.stat(:total_allocated_objects) - x
end
def test
measure_allocations { Foo.new(a: 1) }
end
# We need to warm the callsite before measurement because inline caches are Ruby
# objects, so they will skew our results
test # warmup
test # warmup
p test
If we run the above program with Ruby 3.4.2, we’ll see that the test method allocates 2 objects: and instance of Foo, and a hash for passing the keyword parameters to the C implementation of Class#new.
Achieving an allocation speedup
I want to start first with a little bit of history.
I’ve been interested in speeding up allocations for quite some time.
We know that calling a C function from Ruby incurs some overhead, and that the overhead depends on the type of parameters we pass.
So my initial inclination was to rewrite Class#new in Ruby.
Since Class#new just forwards all of its parameters to initialize, it seemed quite natural to use the triple-dot forwarding syntax (...).
You can find remnants of my initial implementation here.
Unfortunately I found that using ... was quite expensive because at the time, it was syntactic sugar for *, **, &, and Ruby would allocate extra objects to represent these splat parameters.
This lead me to implement an optimization for ....
The optimization for ... allowed us to use parameter forwarding without allocating any extra objects.
I think this optimization is useful in general, but what I had in mind was using it for Class#new.
Fast forward some months, and I was able to implement Class#new in Ruby with this new optimization.
The initial benchmarks were decent, it eliminated allocations and decreased the cost of passing parameters from new to initialize.
But I was somewhat worried about inline cache misses at this call site.
The Class#new implementation linked to above is a little complex, but if we boil it down, it’s essentially the same as the Class#new implementation we saw at the beginning of the post:
class Class
def self.new(...)
instance = allocate
instance.initialize(...)
instance
end
end
The problem with the above code is the inline cache at the initialize call site.
When we make method calls, Ruby will try to cache the destination of that call.
That way we can speed up subsequent calls on the same type at that call site.
CRuby only has a monomorphic inline cache, meaning it can only store one inline cache at any particular call site.
The inline cache is used to help look up the method we will call, and the key to the cache is the class of the receiver (in this case, the class of the instance local variable).
Each time the type of the receiver changes, the cache misses, and we have to do a slow path lookup of the method.
It’s very rare for code to allocate exactly the same type of object many times in a row, so the class of the instance local variable will change quite frequently.
Meaning we could potentially have very poor cache hit rates.
Even if the call site could support multiple cache entries (a “polymorphic” inline cache), the cardinality at this particular call site would be so high that cache hit rates would still be quite poor.
I showed this PR to Koichi Sasada (author of YARV), and he suggested that instead of implementing Class#new in Ruby, we add a new YARV instruction and “inline” the implementation of Class#new.
I worked with John Hawthorn to implement it and we had a prototype implementation done within a week.
Fortunately (or unfortunately) this prototype turned out to be much faster than a Ruby implementation of Class#new, so I decided to abandon that effort.
Inlining Class#new
So what is inlining? Inlining is pretty much just copy / pasting code from the callee to the caller.
Foo.new
Any time the compiler sees code like the above, instead of generating a simple method call to new, it generates the instructions that new would have used but at the call site of new.
To make this more concrete, lets look at the instructions for the above code before and after inlining.
Here is the bytecode for Foo.new before inlining:
> ruby -v --dump=insns -e'Foo.new'
ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [arm64-darwin24]
== disasm: #@-e:1 (1,0)-(1,7)>
0000 opt_getconstant_path ( 1)[Li]
0002 opt_send_without_block
0004 leave
Here is the bytecode for Foo.new after inlining:
> ./ruby -v --dump=insns -e'Foo.new'
ruby 3.5.0dev (2025-04-29T20:36:06Z master b5426826f9) +PRISM [arm64-darwin24]
== disasm: #@-e:1 (1,0)-(1,7)>
0000 opt_getconstant_path ( 1)[Li]
0002 putnil
0003 swap
0004 opt_new , 11
0007 opt_send_without_block
0009 jump 14
0011 opt_send_without_block
0013 swap
0014 pop
0015 leave
Before inlining, the instructions look up the constant Foo, then call the new method.
After inlining, we still look up the constant Foo, but instead of calling the new method, there are a bunch of other instructions.
The most important of these new instructions is the opt_new instruction which allocates a new instance and writes that instance to the stack.
Immediately after the opt_new instruction we see a method call to initialize.
These instructions effectively allocate a new instance and call initialize on that instance, the same thing that Class#new would have done, but without actually calling Class#new.
What’s really nice about this is that any parameters pushed onto the stack are left on the stack for the initialize method to consume.
Where we had to do copies in the C implementation, there are no longer any copies!
Additionally, we no longer push and pop a stack frame for Class#new which further speeds up our code.
Finally, since every call to new includes another call to initialize we have very good cache hit rates compared to the pure Ruby implementation of Class#new.
Rather than one initialize call site, we have an initialize call site at every call to new.
Eliminating a stack frame, eliminating parameter copies, and improving inline cache hits are the major advantages of this optimization.
Downsides to Inlining
Of course this optimization is not without downsides.
First, there are more instructions, so it requires more memory usage.
However, this memory increase only grows in proportion to the number of call sites that use new.
We measured this in our monolith and only saw a 0.5% growth in instruction sequence size, which is an even smaller percentage of overall heap size.
Second, this optimization introduces a small backwards incompatibility. Consider the following code:
class Foo
def initialize
puts caller
end
end
def test
Foo.new
end
test
If we run this code with Ruby 3.4, the output is like this:
> ruby -v test.rb
ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [arm64-darwin24]
test.rb:8:in 'Class#new'
test.rb:8:in 'Object#test'
test.rb:11:in ''
If we run this code with Ruby 3.5, the output is like this:
> ./ruby -v test.rb
ruby 3.5.0dev (2025-04-29T20:36:06Z master b5426826f9) +PRISM [arm64-darwin24]
test.rb:8:in 'Object#test'
test.rb:11:in ''
The Class#new frame is missing from Ruby 3.5 and that is because the frame has been eliminated.
Conclusion
If you’ve made it this far, I hope you found the topic interesting.
I’m really excited for Ruby 3.5 to be released later this year, and I hope you are too!
I want to thank Koichi Sasada for suggesting inlining (and the opt_new instruction) and John Hawthorn for helping me with the implementation.
If you’re curious, take a look at the implementation in the pull request and the discussion in the RedMine ticket.
I didn’t explain every detail of this patch (for example, what happens if you’re calling new on something that isn’t a class?) so if you have questions don’t hesitate to email me or ask on social media.
Have a good day!
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0









