


























27000 Dragons and 10'000 Lights: GPU-Driven Clustered Forward Renderer

During the course Advanced Computer Graphics and Applications I had lots of time (and freedom!) to develop something interesting. While this is an article about computer graphics, it's also about high-performance parallelization strategies.
I have written a GPU-Driven forward rendering using clustered shading. It can render 27'000 stanford dragons with 10'000 lights at 1080p in over 60fps on a GTX 1070 GPU. In this post, I will present exactly how my renderer achieves this performance.

GPU-Driven What?
In a conventional renderer, there is a certain kind of separation in memory and ownership between the GPU and CPU. Usually, the GPU owns texture data, meshes and other assets—while the CPU owns entity data (position, velocity, etc). This is usually a good design, as the entity data is modified many times on the CPU and uploaded once (through a uniform or similar) for each frame to the GPU.
This however, means that certain barriers need to be put up between writing the per-object data and rendering it. Importantly, using a single uniform for all objects requires that each object is rendered sequentially in it's own draw call.
Our goal is to reduce the number of draw calls to as few as possible. In both GL and Vulkan, there is exists an API for indirect multi draws. These differ from normal draw calls in that the CPU dispatches the instruction with the draw details (index count, start vertex index) already present on the GPU in a buffer. This way, a single API call can execute multiple draw calls. It results in a few limitations —for example, re-binding resources or changing shaders between draw calls is not possible—but is a tradeoff for performance.
In my renderer, the entity (object) data is kept in a contigous buffer, and any modifications to it are marked. Before rendering a frame, all modified parts are uploaded to the GPU.
Memory
html
In the above figure, the GPU buffers chosen are shown. As some other renderers do, we share a single GPU buffer for all vertex data. Instead, we use a simple allocator which manages this contigous buffer automatically. This is done for the index buffer as well. There is a drawback to doing this; it requires all vertices to have the same format (same attributes). This can be a problem if there are many different types of meshes in a scene. One solution can be to have a separate vertex buffers for some attributes, which may also improve performance due to cache coherency. For example, one might want to make a separate buffer for animated vertices, or a separate buffer for only the animation attributes (bone ids, weights, etc.).
We also have some unique buffers to this system; namely, the Object Buffer and the Draw Buffer. These contains information that a conventional CPU-driven renderer must provide to the GPU every frame, but are instead stored on device. Objects that are fully static (terrain for example) only needs to be uploaded once. The draw buffer is what actually reduces the number of CPU draw calls (using the aforementioned draw indirect API).
Draw Call Generation
For an optimized renderer, we want to cull objects that are outside the main camera frustum. As you can see from the buffer diagram, we actually have everything we need (except for the camera) to determine what needs to be rendered. As we now create draw calls (into the Draw Buffer) from the GPU, the GPU is now able to cull the scene, which should come with significant speed improvements.
I simplified this by having the meshes store an axis-aligned bounding box (AABB). While other shapes could be used (just prepend a flag), this works well in my cases.
html
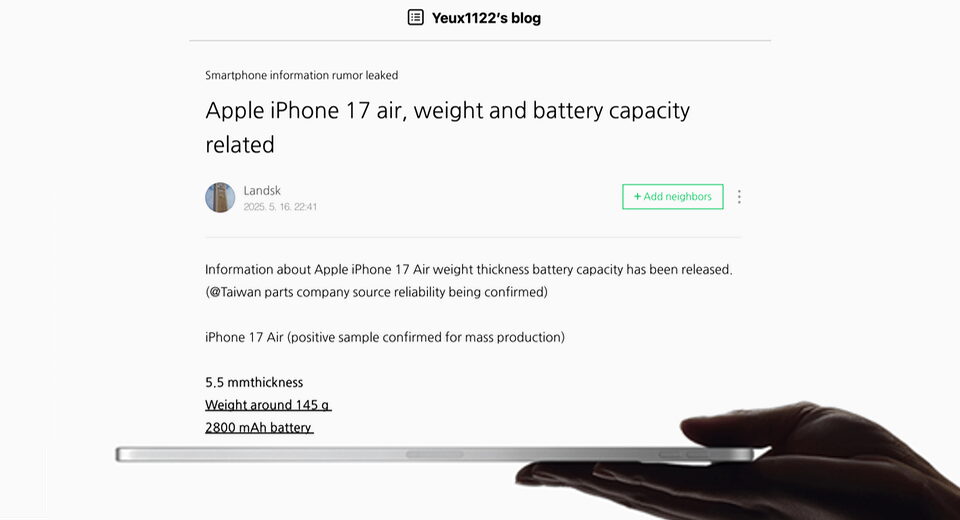
Using a compute shader, elements in the draw buffer are created from each object if that object is visible. A simple implementation is inserting at the same index as the original object definition is in. This means that the culling can be extremely parallelized where each thread of a subgroup culls a single object. One drawback with this design is that the final draw buffer becomes sparse; and therefore requiring more memory than neccessary. If we assume that sometimes all objects are visible, this would be fine as we need a buffer that large. But usually, games might cull as much as 70% or more of the number of objects. A developer runs the game and sees that no more than 50% of all objects are shown in a single frame, meaning that the draw bufer could be as small as 50% of the object buffer. Also, we can expect performance improvements (assuming that compaction is quick) as the draw elements will improve spacial locality. Another thing to consider is that NOP draw indirect calls (that is, calls with 0 vertices), are actually not free, so we can also expect the draw to become quicker.
Running on my GTX 1070, i get a 2.97ms overhead of rendering 125k objects all being culled (avg. 23ns per object).
Special care needs to be taken to support multiple shaders. While I didn't need it, I tried implementing it but met only issues. The problem is that each shader must be assigned an estimation of the number of objects that can be drawn with that shader. Either, you store both draw lists in the same buffer (reserve 70% to shader A, 30% to shader B), or you create 2 different buffers.
Compaction
To support this, we want to compact the elements inserted into the draw buffer such that they reside contigously. This is actually pretty simple to implement using an atomic counter. On the start of each frame, the counter gets reset to zero. For every object which will require rendering, the atomic counter is incremented. Draws are inserted on the index given by the atomic counter.
Simple, yes! Performant? Meh. Well, it is actually pretty simple to optimize this as well. GPU programming is interesting as similar to SIMD-instructions, the most efficient usage comes with great consideration of cooperation. In this case we will use subgroup operation using ballots to speed up cluster compaction.
Ballots are simply a bitset where each thread in the subgroup has ownership of it. For example, each thread can evaluate a boolean and then assign it to their slot in the bitset. It also has cheap operations for evaluating over the whole ballot, like addition, bit count, and more.
I find this algorithm hard to explain, so below I provide both my code and a diagram explaining it.
html
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0









