












Litestream: Revamped

- Author
-

- Name
- Ben Johnson
- @benbjohnson
- @benbjohnson
Litestream is an open-source tool that makes it possible to run many kinds of full-stack applications on top of SQLite by making them reliably recoverable from object storage. This is a post about the biggest change we’ve made to it since I launched it.
Nearly a decade ago, I got a bug up my ass. I wanted to build full-stack applications quickly. But the conventional n-tier database design required me to do sysadmin work for each app I shipped. Even the simplest applications depended on heavy-weight database servers like Postgres or MySQL.
I wanted to launch apps on SQLite, because SQLite is easy. But SQLite is embedded, not a server, which at the time implied that the data for my application lived (and died) with just one server.
So in 2020, I wrote Litestream to fix that.
Litestream is a tool that runs alongside a SQLite application. Without changing that running application, it takes over the WAL checkpointing process to continuously stream database updates to an S3-compatible object store. If something happens to the server the app is running on, the whole database can efficiently be restored to a different server. You might lose servers, but you won’t lose your data.
Litestream worked well. So we got ambitious. A few years later, we built LiteFS. LiteFS takes the ideas in Litestream and refines them, so that we can do read replicas and primary failovers with SQLite. LiteFS gives SQLite the modern deployment story of an n-tier database like Postgres, while keeping the database embedded.
We like both LiteFS and Litestream. But Litestream is the more popular project. It’s easier to deploy and easier to reason about.
There are some good ideas in LiteFS. We’d like Litestream users to benefit from them. So we’ve taken our LiteFS learnings and applied them to some new features in Litestream.
Point-in-time restores, but fast
Here’s how Litestream was originally designed: you run litestream against a SQLite database, and it opens up a long-lived read transaction. This transaction arrests SQLite WAL checkpointing, the process by which SQLite consolidates the WAL back into the main database file. Litestream builds a “shadow WAL” that records WAL pages, and copies them to S3.
This is simple, which is good. But it can also be slow. When you want to restore a database, you have have to pull down and replay every change since the last snapshot. If you changed a single database page a thousand times, you replay a thousand changes. For databases with frequent writes, this isn’t a good approach.
In LiteFS, we took a different approach. LiteFS is transaction-aware. It doesn’t simply record raw WAL pages, but rather ordered ranges of pages associated with transactions, using a file format we call LTX. Each LTX file represents a sorted changeset of pages for a given period of time.
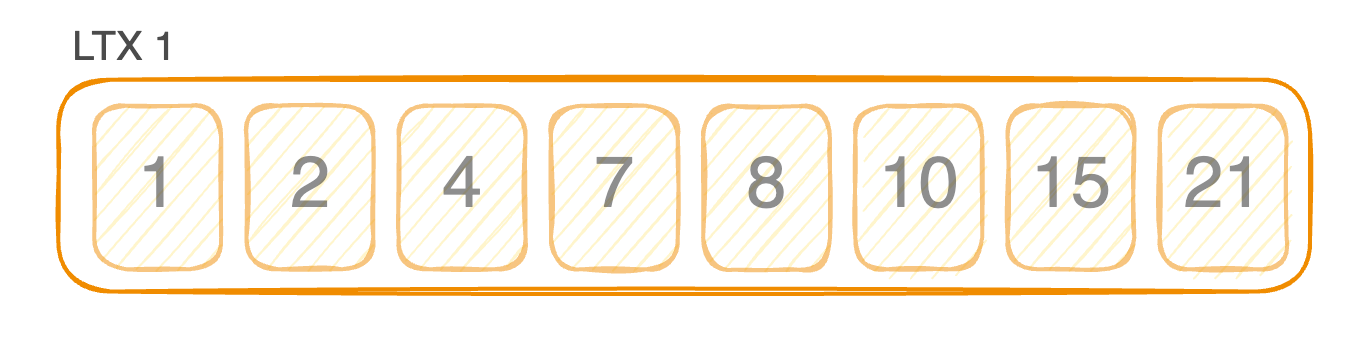
Because they are sorted, we can easily merge multiple LTX files together and create a new LTX file with only the latest version of each page.
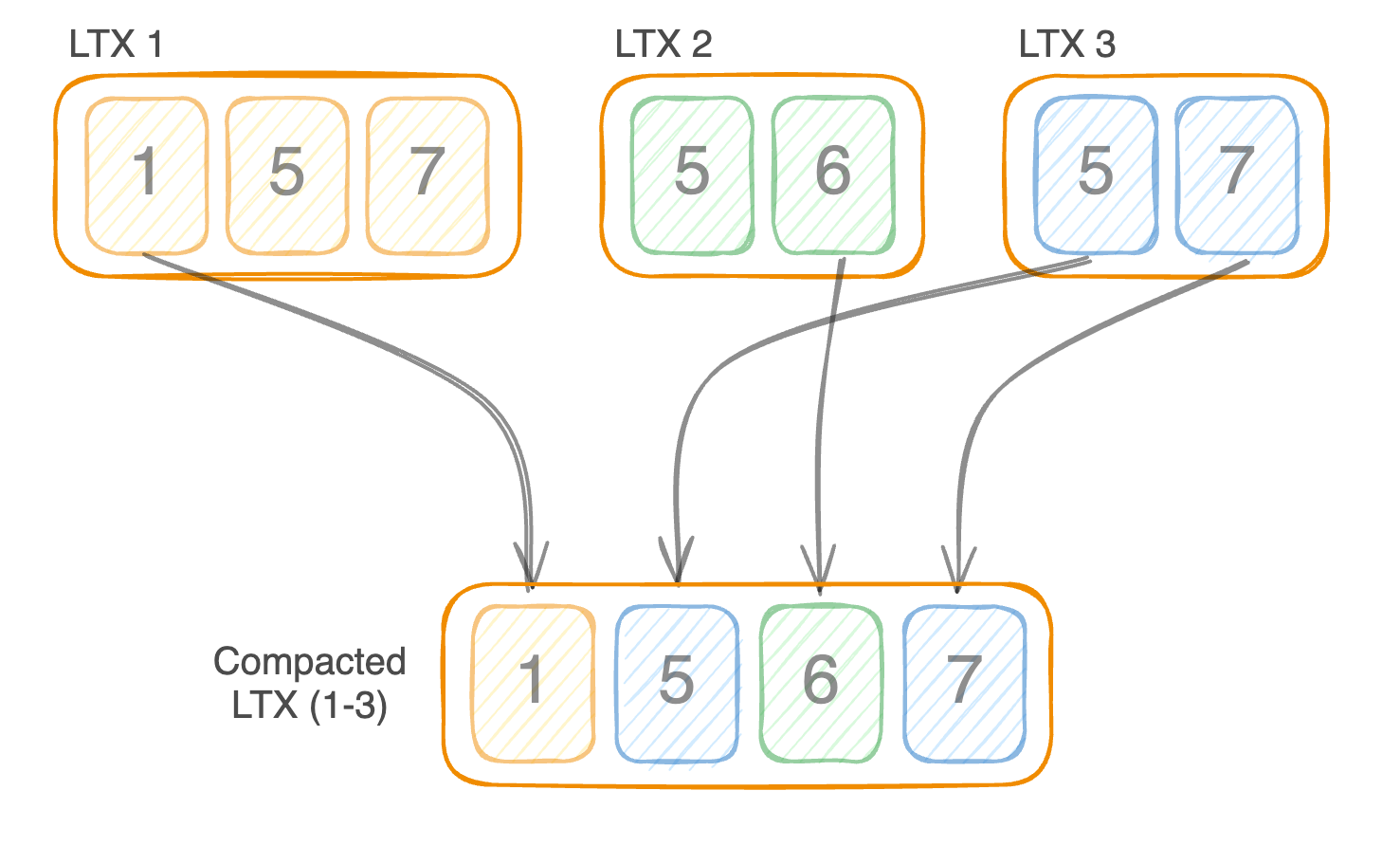
This is similar to how an LSM tree works.
This process of combining smaller time ranges into larger ones is called compaction. With it, we can replay a SQLite database to a specific point in time, with a minimal duplicate pages.
CASAAS: Compare-and-Swap as a Service
One challenge Litestream has to deal with is desynchronization. Part of the point of Litestream is that SQLite applications don’t have to be aware of it. But litestream is just a process, running alongside the application, and it can die independently. If litestream is down while database changes occur, it will miss changes. The same kind of problem occurs if you start replication from a new server.
Litestream needs a way to reset the replication stream from a new snapshot. How it does that is with “generations”. A generation represents a snapshot and a stream of WAL updates, uniquely identified. Litestream notices any break in its WAL sequence and starts a new generation, which is how it recovers from desynchronization.
Unfortunately, storing and managing multiple generations makes it difficult to implement features like failover and read-replicas.
The most straightforward way around this problem is to make sure only one instance of Litestream can replication to a given destination. If you can do that, you can store just a single, latest generation. That in turn makes it easy to know how to resync a read replica; there’s only one generation to choose from.
In LiteFS, we solved this problem by using Consul, which guaranteed a single leader. That requires users to know about Consul. Things like “requiring Consul” are probably part of the reason Litestream is so much more popular than LiteFS.
In Litestream, we’re solving the problem a different way. Modern object stores like S3 and Tigris solve this problem for us: they now offer conditional write support. With conditional writes, we can implement a time-based lease. We get essentially the same constraint Consul gave us, but without having to think about it or set up a dependency.
In the immediacy, this will mean you can run Litestream with ephemeral nodes, with overlapping run times, and even if they’re storing to the same destination, they won’t confuse each other.
The original design constraint of both Litestream and LiteFS was to extend SQLite, to modern deployment scenarios, without disturbing people’s built code. Both tools are meant to function even if applications are oblivious to them.
LiteFS is more ambitious than Litestream, and requires transaction-awareness. To get that without disturbing built code, we use a cute trick (a.k.a. a gross hack): LiteFS provides a FUSE filesystem, which lets it act as a proxy between the application and the backing store. From that vantage point, we can easily discern transactions.
The FUSE approach gave us a lot of control, enough that users could use SQLite replicas just like any other database. But installing and running a whole filesystem (even a fake one) is a lot to ask of users. To work around that problem, we relaxed a constraint: LiteFS can function without the FUSE filesystem if you load an extension into your application code, LiteVFS. LiteVFS is a SQLite Virtual Filesystem (VFS). It works in a variety of environments, including some where FUSE can’t, like in-browser WASM builds.
What we’re doing next is taking the same trick and using it on Litestream. We’re building a VFS-based read-replica layer. It will be able to fetch and cache pages directly from S3-compatible object storage.
Of course, there’s a catch: this approach isn’t as efficient as a local SQLite database. That kind of efficiency, where you don’t even need to think about N+1 queries because there’s no network round-trip to make the duplicative queries pile up costs, is part of the point of using SQLite.
But we’re optimistic that with cacheing and prefetching, the approach we’re using will yield, for the right use cases, strong performance — all while serving SQLite reads hot off of Tigris or S3.
It’s not coupled with Fly.io at all; you can use it anywhere.
Check it out →
Litestream is fully open source

Synchronize Lots Of Databases
While we’ve got you here: we’re knocking out one of our most requested features.
In the old Litestream design, WAL-change polling and slow restores made it infeasible to replicate large numbers of databases from a single process. That has been our answer when users ask us for a “wildcard” or “directory” replication argument for the tool.
Now that we’ve switched to LTX, this isn’t a problem any more. It should thus be possible to replicate /data/*.db, even if there’s hundreds or thousands of databases in that directory.
We Still ❤️ SQLite
SQLite has always been a solid database to build on and it’s continued to find new use cases as the industry evolves. We’re super excited to continue to build Litestream alongside it.
We have a sneaking suspicion that the robots that write LLM code are going to like SQLite too. We think what coding agents like Phoenix.new want is a way to try out code on live data, screw it up, and then rollback both the code and the state. These Litestream updates put us in a position to give agents PITR as a primitive. On top of that, you can build both rollbacks and forks.
Whether or not you’re drinking the AI kool-aid, we think this new design for Litestream is just better. We’re psyched to be rolling it out, and for the features it’s going to enable.
- Previous post ↓
- Launching MCP Servers on Fly.io
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0