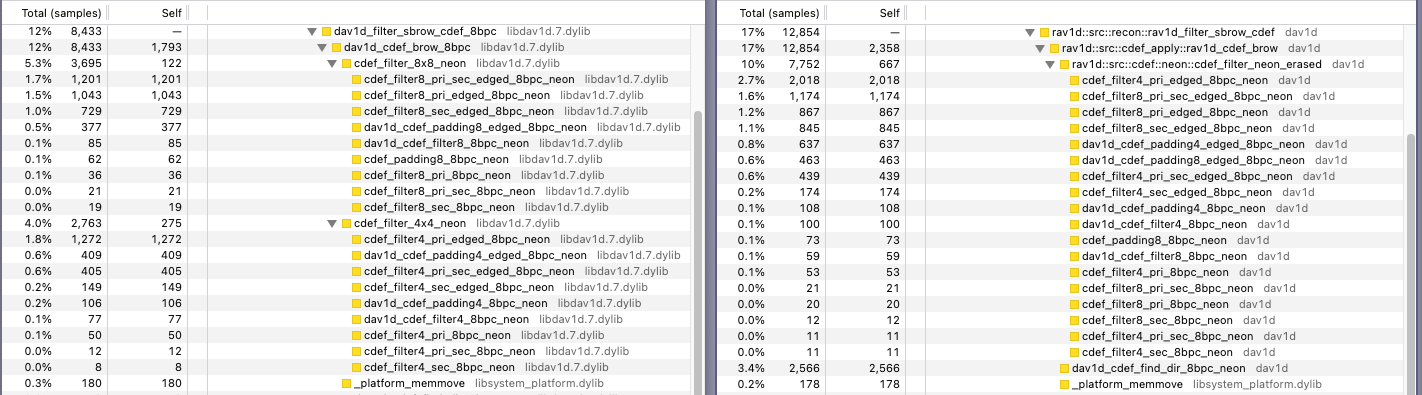




























New #1 open-source AI Agent on SWE-bench Verified

Refact.ai is the #1 open-source AI Agent on SWE-bench Verified with a 69.8% score
Our SWE-bench pipeline is open-source now — check it on GitHub.
Refact.ai Agent achieved 69.8% on SWE-bench Verified — autonomously solving 349 out of 500 tasks. This makes Refact.ai a leading open-source AI programming Agent on SWE-bench and places it among the top ranks on the leaderboard.
SWE-bench Verified is a refined version of the original SWE-bench, featuring 500 real-world GitHub issues, selected manually. It provides a more accurate and consistent way to evaluate how well AI agents can handle practical software engineering tasks.
Key elements that made this possible:
- Extensive guardrails that step in when the model gets stuck or goes off track
- debug_script() sub-agent that uses pdb to fix bugs and can modify/create new scripts
- strategic_planning() tool powered by o3 to rethink and refine fixes when needed
The full pipeline we used for SWE-bench Verified is open-source. You can implement the same components and run the benchmark just like we did — to reproduce Refact.ai Agent approach and score end-to-end.
Read on to see how the Agent is built for SWE-bench, and how the same ideas power real-world workflows in Refact.ai.
Model setup
- Orchestration model: Claude-3.7
- Debug sub-agent —
debug_script(): Claude-3.7 + o4-mini - Planning tool —
strategic_planning(): o3 - pass@1: Each task is not attempted more than once.
- Temperature: 0 for every Claude model.
For each SWE-bench Verified problem, Refact.ai Agent made one multi-step run aiming to produce a single, correct final solution. Our main goal was to achieve a maximum score in a single attempt.
Simpler, more effective Agent prompt
We revised the Agent prompt from our SWE-bench Lite run, where we top-ranked with a 59.7% score. Back then, it was more complex, and looking at how AI Agent behaved, we realized that simpler is better.
The new version is shorter and easier to follow. Since Refact.ai is open-source, you can explore it:
You are a fully autonomous agent for coding tasks.
Your task is to identify and solve the problem from the given PR by directly changing files in the given project.
You must follow the strategy, step by step in the given order without skipping.
**Step 1: Explore the Problem**
- Use `cat()` to open files. Use `search_symbol_definition()`, `search_symbol_usages()` if you know names of symbols.
- Use `search_pattern()` for search by pattern, `search_semantic()` for a semantic search.
**Step 2: Reproduce the Problem using `debug_script()`**
- Find and run all project's existing tests to ensure the fix won't introduce new problems elsewhere.
- Write a script that reproduces the issue. Cover as many corner cases as possible.
- Set up necessary environment (e.g., create required folders or additional files) to run the script.
- Run the script using `shell("python ...")` to verify that the error occurs and the script is correct.
- After verifying that the script is correct and reproduces the issue, call `debug_script()` to debug it.
**Step 3: Make a Plan using `strategic_planning()` and fix the Problem**
- Open all new files mentioned in `debug_script()` report.
- Call `strategic_planning()` once to think through and brainstorm the solution.
- Update projects files directly without creating patches and diffs.
**Step 4: Check and Improve Your Work by running tests**
- Execute the script that reproduces the original issue.
- Run project's existing tests again to ensure the fix doesn't introduce new problems elsewhere.
**BEST PRACTICES**
- You must follow the strategy (explore -> reproduce -> solve -> check), step by step in the given order.
- Before each step explicitly announce your next actions. Make sure they are still align with the strategy.
- Include your thoughts wrapped in Introducing a debugging sub-agent
When developers run into bugs, they investigate the code to figure out what went wrong. For our SWE-bench Verified run, that role was mimicked by debug_script().
debug_script() is a sub-agent inside Refact.ai that uses pdb to debug, modify, and generate scripts. It helps AI Agent gather key issue details:
- Which files are affected
- What actually caused the failure
- And how it might be fixed.
Under the hood, debug_script() is powered by Claude-3.7, with o4-mini for summarizing debug info. We forced Refact.ai Agent to call this tool at least once — and up to three times — during each task.
In practice, this debugging sub-agent was really helpful for digging into the problem source.
4 - Lessons & Recommendations
Pitfalls / anti-patterns
• Converting unchecked user input (blank strings) directly to
• Relying on current working directory semantics leads to environment‐dependent bugs. Codebase insights
•
• No existing test covers the case of blank or empty template dir entries. Suggested fix / next steps
• In • Add a unit test for
• Document that blank entries are dropped and encourage users to validate environment variables before splitting.```Check out an example of its report (click to expand)
1 - Problem Overview
Issue summary
An empty string in the Django `TEMPLATES` 'DIRS' setting can be converted into a root-directory path (`/`), causing the `template_changed()` autoreload hook to always fire (since `/` is in every file's `.parents`).
Expected behaviour
Empty or blank directory entries in `TEMPLATES['DIRS']` should be silently ignored (not converted into `Path("/")`) so that the autoreloader only triggers when actual template directories change.
2 - Project's Files & Symbols Observed
File | Key symbols | Purpose / responsibility
------------------------------------------------------------- | ----------------------------------------------- | ------------------------------------------
/testbed/reproduce_autoreload_issue.py | empty_string, empty_path, template_changed, to_path, Path, test_file, get_template_directories | Test script to reproduce and inspect how empty strings in template dirs are handled
…/django/utils/_os.py | to_path(value) | Utility that turns arbitrary values into `pathlib.Path`
…/python3.X/pathlib.py | Path, Path.__new__, _from_parts, _parse_args, parse_parts, absolute(), resolve(), parents | Standard‐library path‐handling logic, shows how `Path("")` → `"."` → cwd
…/django/template/autoreload.py | template_changed(sender, file_path), get_template_directories() | Hooks into file‐change events to decide when to reload templates
3 - Debugging Timeline
1. Invoked the reproduction script under `pdb`.
2. Stepped to `empty_path = to_path("")`. Confirmed `to_path` simply does `Path("")`.
3. Stepped through `pathlib.Path` internals:
- `Path("")` is parsed as an empty part and becomes `Path(".")` (the current directory).
- `empty_path.absolute()` is therefore the absolute path of the working directory (e.g. `/testbed`).
4. Checked membership:
- `/testbed` was **not** in `/tmp/test_file.py`.parents → no reload.
5. Checked with true root Dir (`Path("/")`):
- `/` **is** in every file's `.parents` → reload always fires.
- Confirmed that the reported issue only occurs when the working directory equals `/`.
6. Inspected Django's `template_changed()` hook:
```python
for template_dir in get_template_directories():
if template_dir in file_path.parents:
reset_loaders()
return True
get_template_directories(): it takes each entry of TEMPLATES['DIRS'] (including empty strings), runs it through to_path(), and collects Path objects without filtering out empties.DIRS = ['', '/some/path']:
Path('') → cwd/, cwd=/ → template_dirs includes / → triggers reload on all file changes./, it is treated as a Template directory and thus matches every changed file.Path without validation.get_template_directories() does not sanitize or skip empty/None entries.get_template_directories(), filter out empty or purely whitespace strings before conversion:raw_dirs = settings.TEMPLATES[…]['DIRS']
cleaned = [d for d in raw_dirs if is instance(d, str) and d.strip()]
template_dirs = [to_path(d) for d in cleaned]TEMPLATES['DIRS'] = ["", "/valid"] to ensure blank entries are ignored.
Guardrails to keep AI Agent on track
The more we tried to constrain the model, the more it resisted. Since the goal was to solve each task in one go, we needed ways to make Agent more reliable.
We added automatic guardrails that kick in when the model gets stuck or makes mistakes. Essentially, these are helper messages, inserted into the chat mid-run as if from a simulated “user” — to nudge Agent back on track. It’s all automated: the script runs static checks on the main model’s (Claude-3.7) messages, and if it detects signs that something is going off track, it sends a message into the chat to help guide the model back in the right direction. These small actions make a big difference in stability.
Extra prompts after sub-agent calls:
After debug_script:
💿 Open all visited files using `cat(file1,file2,file3,…)`!
After strategic_planning():
💿 Now implement the solution above.
Reminders:
- Do not create documents, README.md, or other files which are non-related to fixing the problem.
- Convert generated changes into the `update_textdoc()` or `create_textdoc()` tool calls. Do not creat
patches (in diff format) or monkey-patches!
- Change the project directly to fix the issue but do not modify existing tests.
- Find and run all project’s existing tests to ensure the fix won’t introduce new problems elsewhere.
- Create new test files only using `create_textdoc()`.
Guardrails for Agent flow:
💿 Use `debug_script()` instead of `shell()`; dig deeper than previous attempts and set breakpoints inside the project. 💿 Do not call `debug_script()` more than three times. 💿 Call `strategic_planning()` before modifying the project. 💿 If you struggle to find the correct solution, consider using `debug_script()` or `strategic_planning()`. 💿 You cannot call {a_tool_name}\ while on the previous step—follow the strategy.
Strategic planning
The strategic_planning() tool comes in at Step 3 of the Agent prompt. It helps the model improve solution quality by reflecting on what went wrong — and what could be done better — based on the debug_script() report. It uses reasoning, powered by o3, and updates project files directly, without generating patches and diffs.
For this tool, we enforce one call per task.
Since the observation layer (search + pdb debug) was already quite efficient, strategy planning sometimes lagged. We tried the o4-mini and o3 models and found no obvious differences on a small subset of tasks. That said, both models were prone to overcomplicating tasks or not smart enough to identify the real root cause. Claude 3.7 might be a good candidate as a planning model in the future, given how well it did in other parts of the workflow.
Improvements over the SWE-bench Lite strategy
A 59.7% score on the SWE-bench Lite was a solid start. We shared the full technical breakdown in our earlier blog post — but even with a SOTA result, this run exposed a few weak spots.
Before tackling SWE-bench Verifies, we prioritized addressing these issues found.
Tools-related updates:
- Fixed a few tool-related issues, making the tools more tolerant of the model’s uncertainty when calling them.
- Renamed tools — the model often skipped some tools as their names were unclear. New names:
definition() -> search\_symbol\_definition()
references() -> search\_symbol\_usages()
regex\_search() -> search\_pattern()
search() -> search\_semantic()
deep\_analysis() -> strategic\_planning() - Fixed the AST mechanisms inside refact-lsp that prevented decorated symbols from being parsed.
- Resolved an issue where Agent didn’t wait for ast/vecdb to finish indexing the project.
- We now mark line numbers, which add extra stability with retrieval tools like cat, search, etc.
Context-related updates:
- Reduced the strength of chat compression. Claude 3.7 often tried to
catfiles already in context; instead of blocking it (which caused loops), we now allow the model to receive them again. - Encouraged the model to open whole files instead of many tiny
catcalls to read a file line by line. - When the model opens large files, it noticeably degrades as the context size grows quickly. We continue to adjust this balance.
During the SWE-bench Verified run, all these improvements were implemented.
What we tried that did not work
Not every experiment make it to production. Here’s what we tested — and what we implemented:
| Didn’t work | What works instead |
|---|---|
A separate critique tool that allowed the model to assess its own changes. | Turns out, the model does better when it just runs tests and decides the next steps based on results. |
A complex strategic_planning () tool flow with four steps: root-cause analysis → initial solution → critique → refined solution. It overcomplicated simple tasks and lowered success rates. | Now, strategic_planning() only generates a solution — and this works better. |
Using a pdb() tool without a dedicated sub-agent. The Claude model preferred shell() over pdb(), so debugging rarely happened. | Introducing the debug_script() sub-agent made it reliable. |
| Running without sub-agents. As context grew, Claude 3.7 quickly became less accurate and stopped following instructions. | Letting sub-agents do their job. |
From benchmark to real product
What makes Refact.ai stand out isn’t just the % of solved benchmark tasks — it’s how our AI Agent gets there. Our goal isn’t to win all leaderboards just for the sake of it, but to build an approach that actually works for real-world programming.
That’s why SWE-bench Verified is also a way to test and improve the actual engineering flow of our product. Many of the updates we made for the run (see: Tools-related updates, Context-related updates) are already shipping in Refact.ai.
The guard mechanisms are another example: in the product, we already have these helper messages that AI Agent automatically sends itself after calling certain tools. Like with debug_script(): it gets the tool output, and also a static instruction to open all the related files mentioned. So, these guard mechanisms are already part of specific flows. And we’re planning more, incluiding chat-wide checks to spot earlier off-tracks and react to them.
We’re also updating the AI Agent prompt used in Refact.ai for VS Code and JetBrains to improve product efficiency for our users. Notably, strategic_planning() isn’t (and won’t be) called by default in pluggin — it’s heavy on coins spent and not always necessary, since the main model is often enough to solve the task. That said, if you think your task needs deeper reasoning, you can still call it manually in chat with @. Just keep in mind it’s coin-expensive.
Refact.ai Agent solved SWE-bech Verified fully autonomously — but in real-world use, of course, developers often want more control. That’s why Refact.ai offers flexible interaction with manual overrides: you can delegate tasks to AI Agent, while it lets you preview and guide the process.
That reflects our philosophy: autonomous AI Agent for programming you can trust — and control when you need to.
Final score
Out of 500 tasks in SWE-bench Verified:
- 🥇 Solved: 349 (69,8% resolve rate)
- Not solved: 151 (30,2%).
Evaluation results
| Total Instances | Solved | Not solved | Solved (%) | Not solved (%) |
|---|---|---|---|---|
| 500 | 349 | 151 | 69,8% | 30,2% |
Resolved by Repository:
astropy/astropy: 9/22 (40.91%) django/django: 165/231 (71.43%) matplotlib/matplotlib: 20/34 (58.82%) mwaskom/seaborn: 0/2 (0.0%) pallets/flask: 1/1 (100.0%) psf/requests: 6/8 (75.0%) pydata/xarray: 18/22 (81.82%) pylint-dev/pylint: 4/10 (40.0%) pytest-dev/pytest: 16/19 (84.21%) scikit-learn/scikit-learn: 28/32 (87.5%) sphinx-doc/sphinx: 28/44 (63.64%) sympy/sympy: 54/75 (72.0%)
Resolved by Time:
2013: 3/3 (100.0%) 2014: 2/2 (100.0%) 2015: 0/1 (0.0%) 2016: 2/2 (100.0%) 2017: 13/16 (81.25%) 2018: 14/24 (58.33%) 2019: 73/98 (74.49%) 2020: 79/108 (73.15%) 2021: 54/86 (62.79%) 2022: 71/102 (69.61%) 2023: 38/58 (65.52%)
Get Refact.ai Agent for your IDE
Refact.ai is an autonomous AI Agent that automates programming tasks — helping developers and IT teams move faster:
With Refact.ai in your IDE, you get:
- Real automation that boosts productivity by 10x
- Seamless integration with your codebase, workflow, and dev tools
- A digital twin that handles your busywork and lets you focus on big things.
Available to everyone: install Refact.ai for VS Code or JetBrains today and feel the real impact in your everyday programming.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0