























I got fooled by AI-for-science hype–here's what it taught me

I’m excited to publish this guest post by Nick McGreivy, a physicist who last year earned a PhD from Princeton. Nick used to be optimistic that AI could accelerate physics research. But when he tried to apply AI techniques to real physics problems the results were disappointing.
I’ve written before about the Princeton School of AI Safety, which holds that the impact of AI is likely to be similar to that of past general-purpose technologies such as electricity, integrated circuits, and the Internet. I think of this piece from Nick as being in that same intellectual tradition.
—Timothy B. Lee
In 2018, as a second-year PhD student at Princeton studying plasma physics, I decided to switch my research focus to machine learning. I didn’t yet have a specific research project in mind, but I thought I could make a bigger impact by using AI to accelerate physics research. (I was also, quite frankly, motivated by the high salaries in AI.)
I eventually chose to study what AI pioneer Yann LeCun later described as a “pretty hot topic, indeed”: using AI to solve partial differential equations (PDEs). But as I tried to build on what I thought were impressive results, I found that AI methods performed much worse than advertised.
At first, I tried applying a widely-cited AI method called PINN to some fairly simple PDEs, but found it to be unexpectedly brittle. Later, though dozens of papers had claimed that AI methods could solve PDEs faster than standard numerical methods—in some cases as much as a million times faster—I discovered that a large majority of these comparisons were unfair. When I compared these AI methods on equal footing to state-of-the-art numerical methods, whatever narrowly defined advantage AI had usually disappeared.
This experience has led me to question the idea that AI is poised to “accelerate” or even “revolutionize” science. Are we really about to enter what DeepMind calls “a new golden age of AI-enabled scientific discovery,” or has the overall potential of AI in science been exaggerated—much like it was in my subfield?
Many others have identified similar issues. For example, in 2023 DeepMind claimed to have discovered 2.2 million crystal structures, representing “an order-of-magnitude expansion in stable materials known to humanity.” But when materials scientists analyzed these compounds, they found it was “mostly junk” and “respectfully” suggested that the paper “does not report any new materials.”
Separately, Princeton computer scientists Arvind Narayanan and Sayash Kapoor have compiled a list of 648 papers across 30 fields that all make a methodological error called data leakage. In each case data leakage leads to overoptimistic results. They argue that AI-based science is facing a “reproducibility crisis.”
Yet AI adoption in scientific research has been rising sharply over the last decade. Computer science has seen the biggest impacts, of course, but other disciplines—physics, chemistry, biology, medicine, and the social sciences—have also seen rapidly increasing AI adoption. Across all scientific publications, rates of AI usage grew from 2 percent in 2015 to almost 8 percent in 2022. It’s harder to find data about the last few years, but there’s every reason to think that hockey stick growth has continued.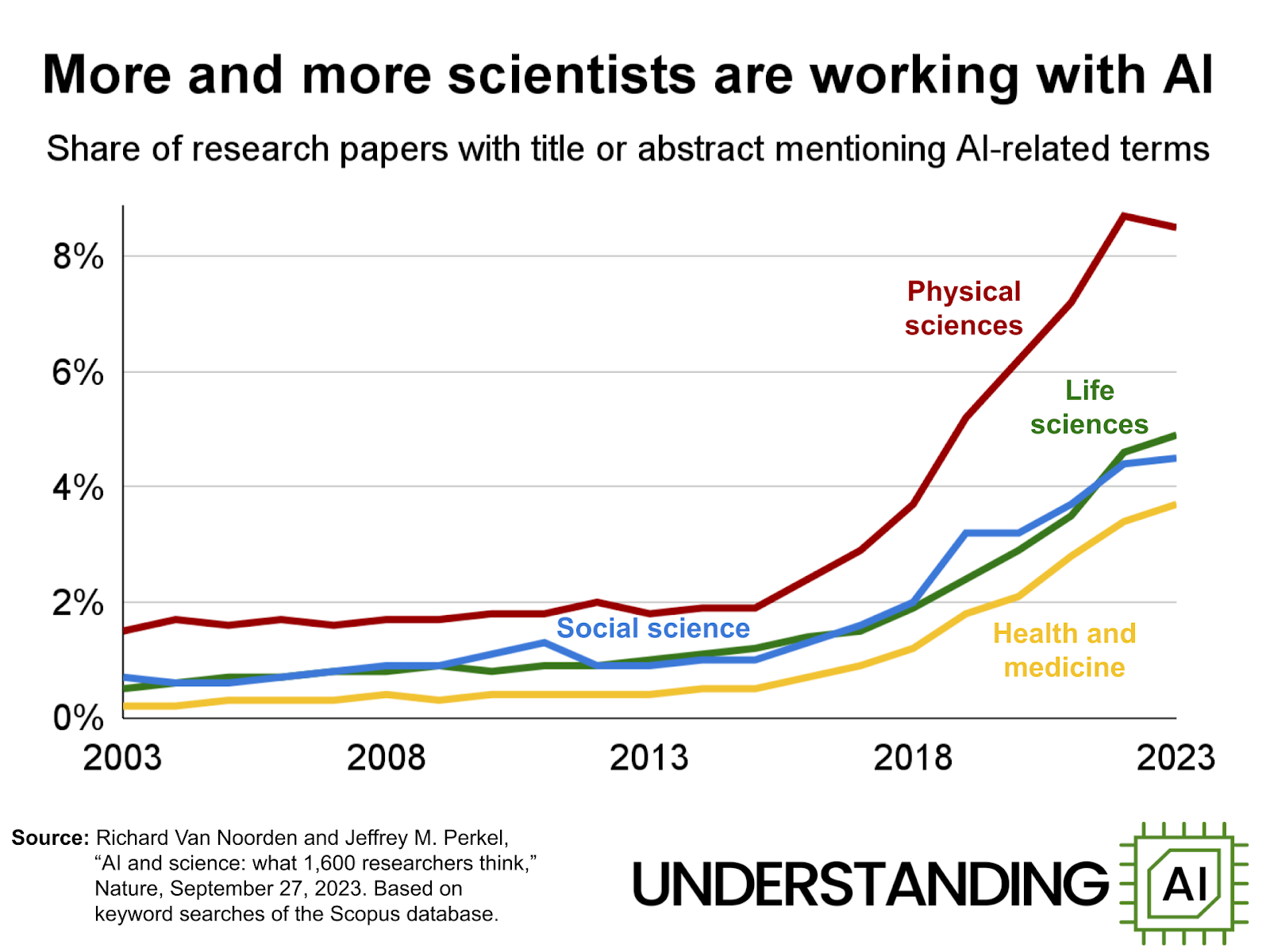
To be clear, AI can drive scientific breakthroughs. My concern is about their magnitude and frequency. Has AI really shown enough potential to justify such a massive shift in talent, training, time, and money away from existing research directions and towards a single paradigm?
Every field of science is experiencing AI differently, so we should be cautious about making generalizations. I’m convinced, however, that some of the lessons from my experience are broadly applicable across science:
AI adoption is exploding among scientists less because it benefits science and more because it benefits the scientists themselves.
Because AI researchers almost never publish negative results, AI-for-science is experiencing survivorship bias.
The positive results that get published tend to be overly optimistic about AI’s potential.
As a result, I’ve come to believe that AI has generally been less successful and revolutionary in science than it appears to be.
Ultimately, I don’t know whether AI will reverse the decades-long trend of declining scientific productivity and stagnating (or even decelerating) rates of scientific progress. I don’t think anyone does. But barring major (and in my opinion unlikely) breakthroughs in advanced AI, I expect AI to be much more a normal tool of incremental, uneven scientific progress than a revolutionary one.
My disappointing experience with PINNs
In the summer of 2019, I got a first taste of what would become my dissertation topic: solving PDEs with AI. PDEs are mathematical equations used to model a wide range of physical systems, and solving (i.e., simulating) them is an extremely important task in computational physics and engineering. My lab uses PDEs to model the behavior of plasmas, such as inside fusion reactors and in the interstellar medium of outer space.
The AI models being used to solve PDEs are custom deep learning models, much more analogous to AlphaFold than ChatGPT.
The first approach I tried was something called the physics-informed neural network. PINNs had recently been introduced in an influential paper that had already racked up hundreds of citations.
PINNs were a radically different way of solving PDEs compared to standard numerical methods. Standard methods represent a PDE solution as a set of pixels (like in an image or video) and derive equations for each pixel value. In contrast, PINNs represent the PDE solution as a neural network and put the equations into the loss function.
As a naive grad student who didn’t even have an advisor yet, there was something incredibly appealing to me about PINNs. They just seemed so simple, elegant, and general.
They also seemed to have good results. The paper introducing PINNs found that their “effectiveness” had been “demonstrated through a collection of classical problems in fluids, quantum mechanics, reaction-diffusion systems, and the propagation of nonlinear shallow-water waves.” If PINNs had solved all these PDEs, I figured, then surely they could solve some of the plasma physics PDEs that my lab cared about.
But when I replaced one of the examples from that influential first paper (1D Burgers’) with a different, but still extremely simple, PDE (1D Vlasov), the results didn’t look anything like the exact solution. Eventually, after extensive tuning, I was able to get something that looked correct. However, when I tried slightly more complex PDEs (such as 1D Vlasov-Poisson), no amount of tuning could give me a decent solution.
After a few weeks of failure, I messaged a friend at a different university, who told me that he too had tried using PINNs, but hadn’t been able to get good results.
What I learned from my PINN experiments
Eventually, I realized what had gone wrong. The authors of the original PINN paper had, like me, “observed that specific settings that yielded impressive results for one equation could fail for another.” But because they wanted to convince readers of how exciting PINNs were, they hadn’t shown any examples of PINNs failing.
This experience taught me a few things. First, to be cautious about taking AI research at face value. Most scientists aren’t trying to mislead anyone, but because they face strong incentives to present favorable results, there’s still a risk that you’ll be misled. Moving forward, I would have to be more skeptical, even (or perhaps especially) of high-impact papers with impressive results.
Second, people rarely publish papers about when AI methods fail, only when they succeed. The authors of the original PINN paper didn’t publish about the PDEs their method hadn’t been able to solve. I didn’t publish my unsuccessful experiments, presenting only a poster at an obscure conference. So very few researchers heard about them. In fact, despite the huge popularity of PINNs, it took four years for anyone to publish a paper about their failure modes. That paper now has almost a thousand citations, suggesting that many other scientists tried PINNs and found similar issues.
Third, I concluded that PINNs weren’t the approach I wanted to use. They were simple and elegant, sure, but they were also far too unreliable, too finicky, and too slow.
As of today, six years later, the original PINN paper has a whopping 14,000 citations, making it the most cited numerical methods paper of the 21st century (and, by my count, a year or two away from becoming the second most-cited numerical methods paper of all time).
Though it’s now widely accepted that PINNs generally aren’t competitive with standard numerical methods for solving PDEs, there remains debate over how well PINNs perform for a different class of problems known as inverse problems. Advocates claim that PINNs are “particularly effective” for inverse problems, but some researchers have vigorously contested that idea.
I don’t know which side of the debate is right. I’d like to think that something useful has come from all this PINN research, but I also wouldn’t be surprised if one day we look back on PINNs as simply a massive citation bubble.
Weak baselines lead to overoptimism
For my dissertation, I focused on solving PDEs using deep learning models that, like traditional solvers, treated the PDE solution as a set of pixels on a grid or a graph.
Unlike PINNs, this approach had shown a lot of promise on the complex, time-dependent PDEs that my lab cared about. Most impressively, paper after paper had demonstrated the ability to solve PDEs faster—often orders of magnitude faster—than standard numerical methods.
The examples that excited my advisor and me the most were PDEs from fluid mechanics, such as the Navier-Stokes equations. We thought we might see similar speedups because the PDEs we cared about—equations describing plasmas in fusion reactors, for example—have a similar mathematical structure. In theory, this could allow scientists and engineers like us to simulate larger systems, more rapidly optimize existing designs, and ultimately accelerate the pace of research.
By this point, I was seasoned enough to know that in AI research, things aren’t always as rosy as they seem. I knew that reliability and robustness might be serious issues. If AI models give faster simulations, but those simulations are less reliable, would that be worth the trade-off? I didn’t know the answer and set out to find out.
But as I tried—and mostly failed—to make these models more reliable, I began to question how much promise AI models had really shown for accelerating PDEs.
According to a number of high-profile papers, AI had solved the Navier-Stokes equations orders of magnitude faster than standard numerical methods. I eventually discovered, however, that the baseline methods used in these papers were not the fastest numerical methods available. When I compared AI to more advanced numerical methods, I found that AI was no faster (or at most, only slightly faster) than the stronger baselines.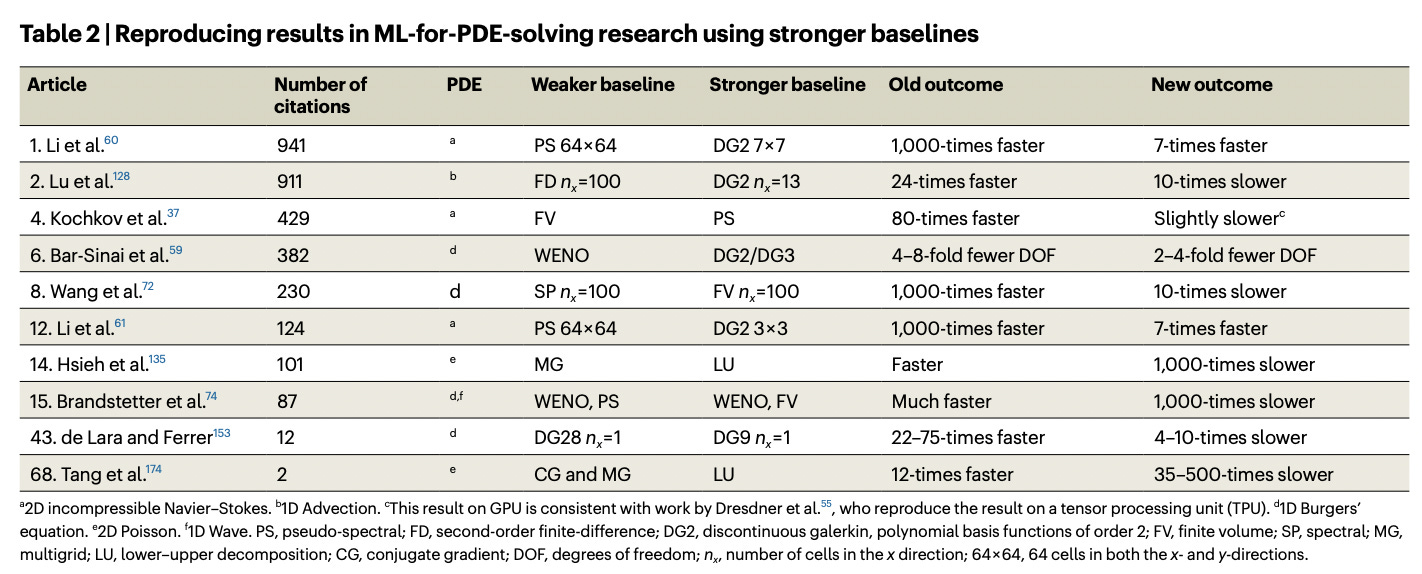
My advisor and I eventually published a systematic review of research using AI to solve PDEs from fluid mechanics. We found that 60 out of the 76 papers (79 percent) that claimed to outperform a standard numerical method had used a weak baseline, either because they hadn’t compared to more advanced numerical methods, or because they weren’t comparing them on an equal footing. Papers with large speedups all compared to weak baselines, suggesting that the more impressive the result, the more likely the paper had made an unfair comparison.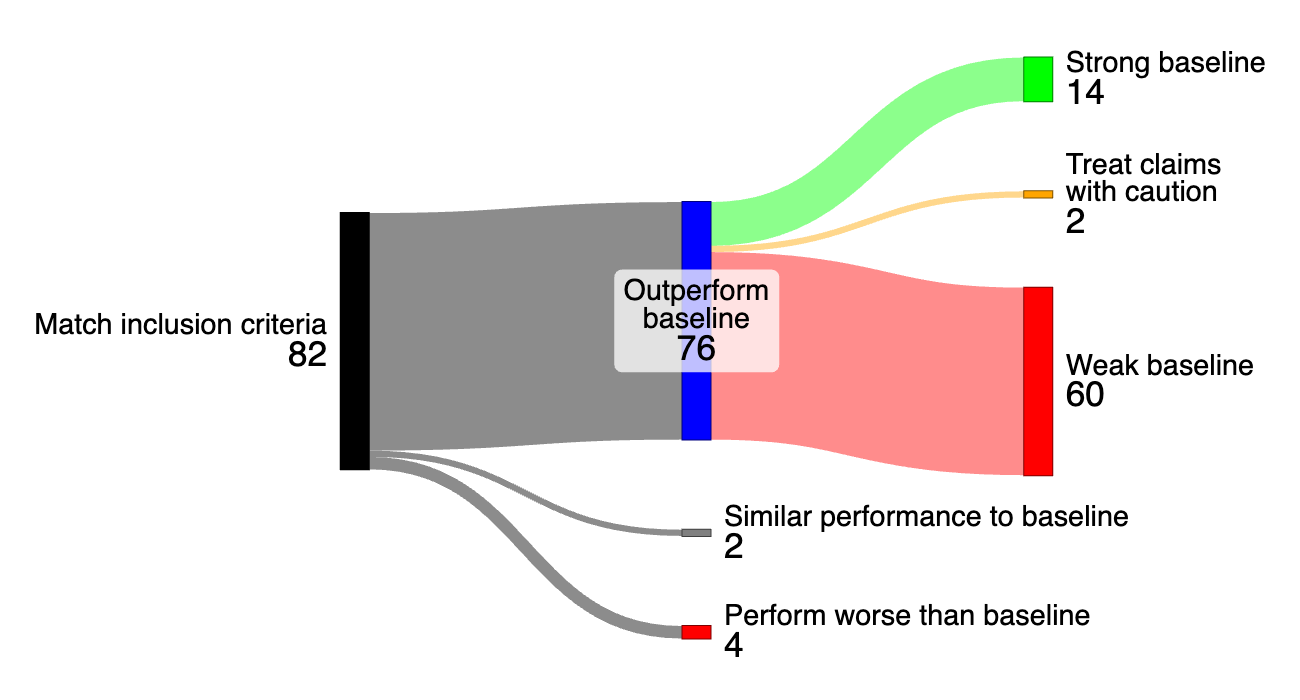
We also found evidence, once again, that researchers tend not to report negative results, an effect known as reporting bias. We ultimately concluded that AI-for-PDE-solving research is overoptimistic: “weak baselines lead to overly positive results, while reporting biases lead to under-reporting of negative results.”
These findings sparked a debate about AI in computational science and engineering:
Lorena Barba, a professor at GWU who has previously discussed poor research practices in what she has called “Scientific Machine Learning to Fool the Masses,” saw our results as “solid evidence supporting our concerns in the computational science community over the hype and unscientific optimism” of AI.
Stephan Hoyer, the lead of a team at Google Research that independently reached similar conclusions, described our paper as “a nice summary of why I moved on from [AI] for PDEs” to weather prediction and climate modeling, applications of AI that seem more promising.
Johannes Brandstetter, a professor at JKU Linz and co-founder of a startup that provides “AI-driven physics simulations”, argued that AI might achieve better results for more complex industrial applications and that “the future of the field remains undeniably promising and brimming with potential impact.”
In my opinion, AI might eventually prove useful for certain applications related to solving PDEs, but I currently don’t see much reason for optimism. I’d like to see a lot more focus on trying to match the reliability of numerical methods and on red teaming AI methods; right now, they have neither the theoretical guarantees nor empirically validated robustness of standard numerical methods.
I’d also like to see funding agencies incentivize scientists to create challenge problems for PDEs. A good model could be CASP, a biennial protein folding competition that helped to motivate and focus research in this area over the last 30 years.
Will AI accelerate science?
Besides protein folding, the canonical example of a scientific breakthrough from AI, a few examples of scientific progress from AI include:
Weather forecasting, where AI forecasts have had up to 20% higher accuracy (though still lower resolution) compared to traditional physics-based forecasts.
Drug discovery, where preliminary data suggests that AI-discovered drugs have been more successful in Phase I (but not Phase II) clinical trials. If the trend holds, this would imply a nearly twofold increase in end-to-end drug approval rates.
But AI companies, academic and governmental organizations, and media outlets increasingly present AI not only as a useful scientific tool, but one that “will have a transformational impact” on science.
I don’t think we should necessarily dismiss these statements. While current LLMs, according to DeepMind, “still struggle with the deeper creativity and reasoning that human scientists rely on”, hypothetical advanced AI systems might one day be capable of fully automating the scientific process. I don’t expect that to happen anytime soon—if ever. But if such systems are created, there’s no doubt they would transform and accelerate science.
However, based on some of the lessons from my research experience, I think we should be pretty skeptical of the idea that more conventional AI techniques are on pace to significantly accelerate scientific progress.
Lessons about AI in science
Most narratives about AI accelerating science come from AI companies or scientists working on AI who benefit, directly or indirectly, from those narratives. For example, NVIDIA CEO Jensen Huang talks about how “AI will drive scientific breakthroughs” and “accelerate science by a million-X.” NVIDIA, whose financial conflicts of interest make them a particularly unreliable narrator, regularly makes hyperbolic statements about AI in science.
You might think that the rising adoption of AI by scientists is evidence of AI’s usefulness in science. After all, if AI usage in scientific research is growing exponentially, it must be because scientists find it useful, right?
I’m not so sure. In fact, I suspect that scientists are switching to AI less because it benefits science, and more because it benefits them.
Consider my motives for switching to AI in 2018. While I sincerely thought that AI might be useful in plasma physics, I was mainly motivated by higher salaries, better job prospects, and academic prestige. I also noticed that higher-ups at my lab usually seemed more interested in the fundraising potential of AI than technical considerations.
Later research found that scientists who use AI are more likely to publish top-cited papers and receive on average three times as many citations. With such strong incentives to use AI, it isn’t surprising that so many scientists are doing so.
So even when AI achieves genuinely impressive results in science, that doesn’t mean that AI has done something useful for science. More often, it reflects only the potential of AI to be useful down the road.
This is because scientists working on AI (myself included) often work backwards. Instead of identifying a problem and then trying to find a solution, we start by assuming that AI will be the solution and then looking for problems to solve. But because it’s difficult to identify open scientific challenges that can be solved using AI, this “hammer in search of a nail” style of science means that researchers will often tackle problems which are suitable for using AI but which either have already been solved or don't create new scientific knowledge.
To accurately evaluate the impacts of AI in science, we need to actually look at the science. But unfortunately, the scientific literature is not a reliable source for evaluating the success of AI in science.
One issue is survivorship bias. Because AI research, in the words of one researcher, has “nearly complete non-publication of negative results,” we usually only see the successes of AI in science and not the failures. But without negative results, our attempts to evaluate the impacts of AI in science typically get distorted.
As anyone who’s studied the replication crisis knows, survivorship bias is a major issue in science. Usually, the culprit is a selection process in which results that are not statistically significant are filtered from the scientific literature.
For example, the distribution of z-values from medical research is shown below. A z-value between -1.96 and 1.96 indicates that a result is not statistically significant. The sharp discontinuity around these values suggests that many scientists either didn’t publish results between these values or massaged their data until they cleared the threshold of statistical significance.
The problem is that if researchers fail to publish negative results, it can cause medical practitioners and the general public to overestimate the effectiveness of medical treatments.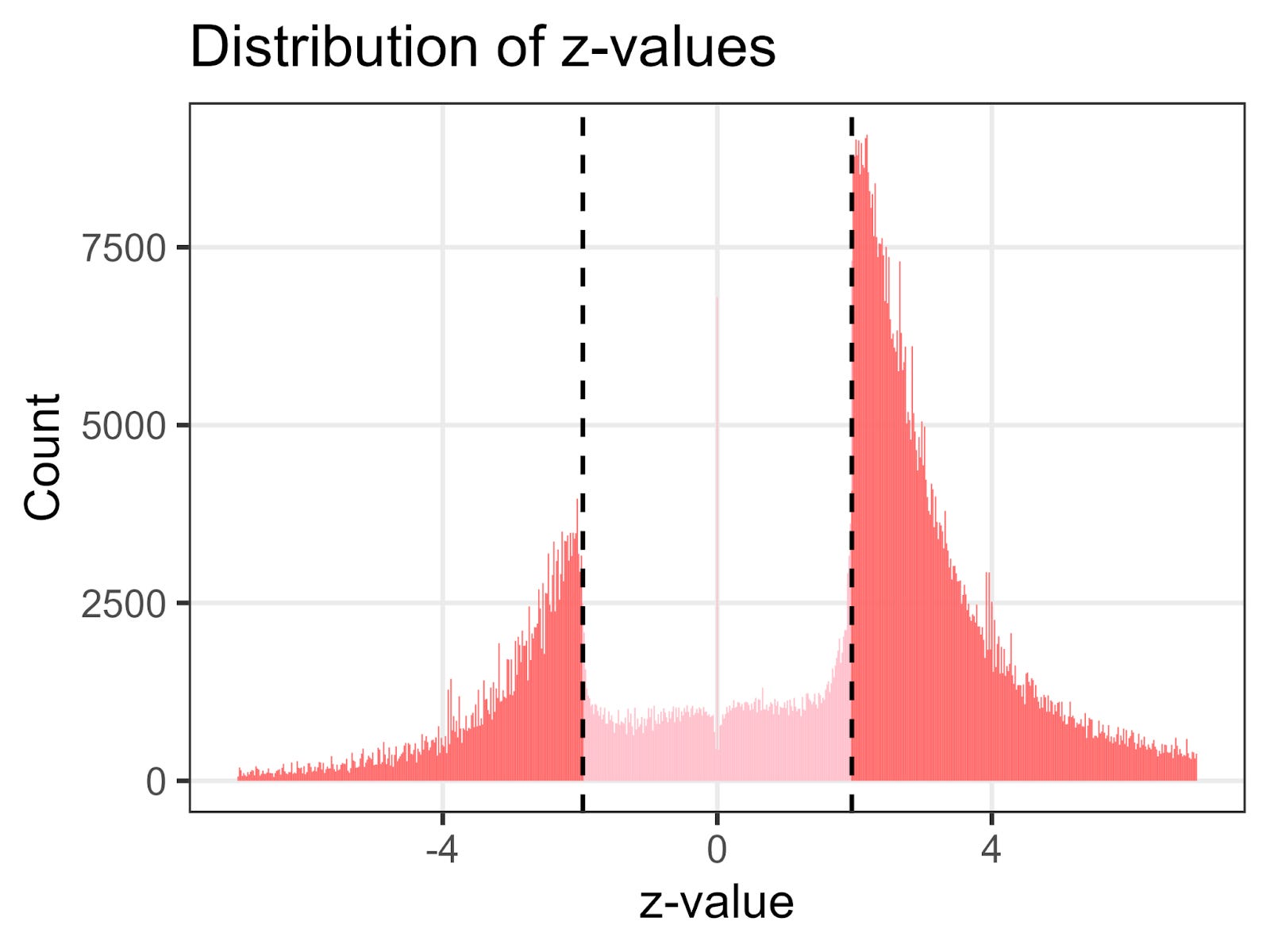
Something similar has been happening in AI-for-science, though the selection process is based not on statistical significance but on whether the proposed method outperforms other approaches or successfully performs some novel task. This means that AI-for-science researchers almost always report successes of AI, and rarely publish results when AI isn’t successful.
A second issue is that pitfalls often cause the successful results that do get published to reach overly optimistic conclusions about AI in science. The details and severity seem to differ between fields, but pitfalls mostly have fallen into one of four categories: data leakage, weak baselines, cherry-picking, and misreporting.
While the causes of this tendency towards overoptimism are complex, the core issue appears to be a conflict of interest in which the same people who evaluate AI models also benefit from those evaluations.
These issues seem to be bad enough that I encourage people to treat impressive results in AI-for-science the same way we treat surprising results in nutrition science: with instinctive skepticism.
Early drafts of this article gave three examples here, including a paper by MIT graduate student Aidan Toner-Rodgers about the use of AI to discover new materials. That paper had been described as “the best paper written so far about the impact of AI on scientific discovery”. But then MIT announced that it was seeking the retraction of the paper due to concerns “about the integrity of the research.” Of course, allegations of outright fraud are a different issue than the subtler methodological problems I focus on in my article. But the fact that this paper got so much traction in the media underscores my broader point that researchers have a variety of incentives to exaggerate the effectiveness of AI techniques.
When I talk about scientists using AI, I mean training or using special-purpose AI models such as PINNs or AlphaFold. I’m not talking about using an LLM to help write grant proposals or do basic background research.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0









