












Gemini Diffusion
Gemini Diffusion. Another of the announcements from Google I/O yesterday was Gemini Diffusion, Google's first LLM to use diffusion (similar to image models like Imagen and Stable Diffusion) in place of transformers.
Google describe it like this:
Traditional autoregressive language models generate text one word – or token – at a time. This sequential process can be slow, and limit the quality and coherence of the output.
Diffusion models work differently. Instead of predicting text directly, they learn to generate outputs by refining noise, step-by-step. This means they can iterate on a solution very quickly and error correct during the generation process. This helps them excel at tasks like editing, including in the context of math and code.
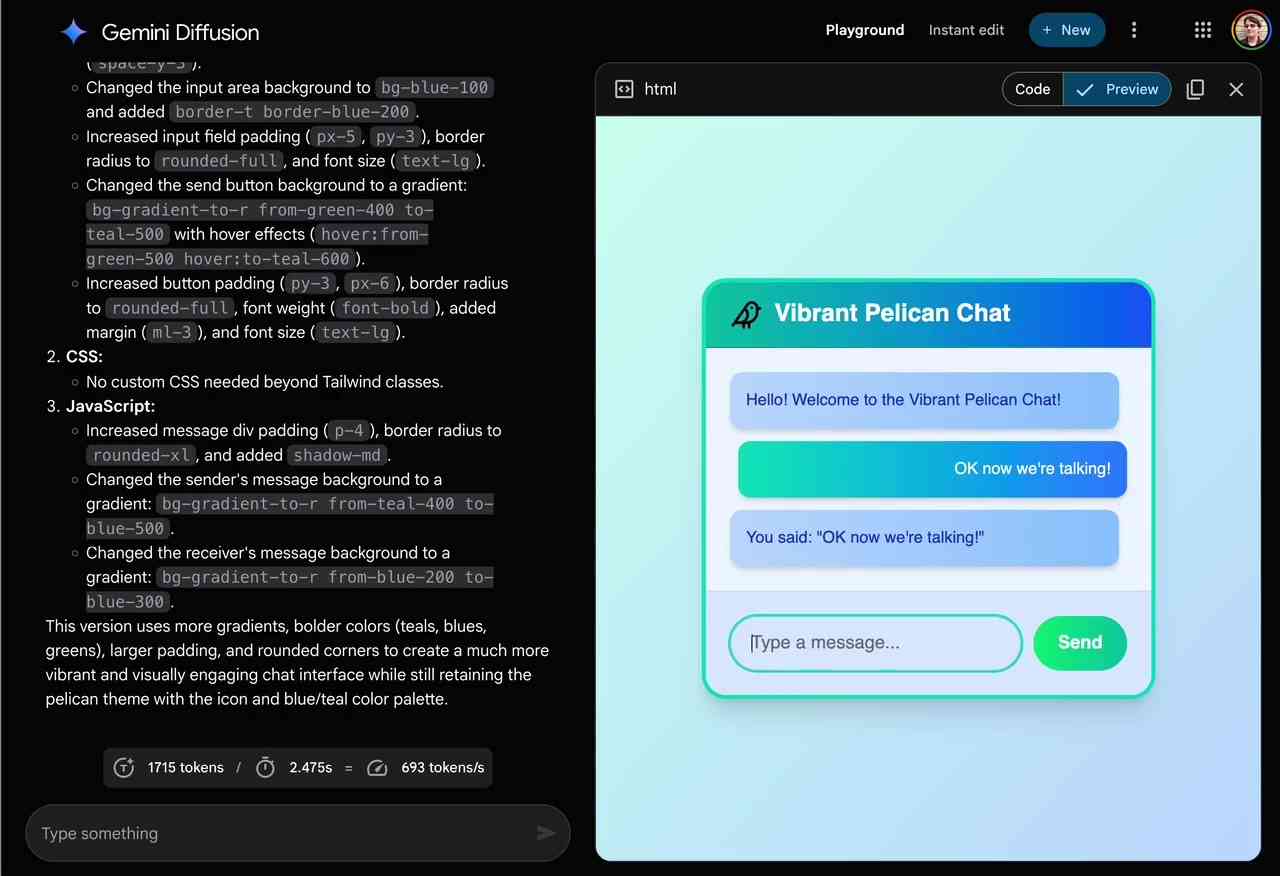
The key feature then is speed. I made it through the waitlist and tried it out just now and wow, they are not kidding about it being fast.
In this video I prompt it with "Build a simulated chat app" and it responds at 857 tokens/second, resulting in an interactive HTML+JavaScript page (embedded in the chat tool, Claude Artifacts style) within single digit seconds.
The performance feels similar to the Cerebras Coder tool, which used Cerebras to run Llama3.1-70b at around 2,000 tokens/second.
How good is the model? I've not seen any independent benchmarks yet, but Google's landing page for it promises "the performance of Gemini 2.0 Flash-Lite at 5x the speed" so presumably they think it's comparable to Gemini 2.0 Flash-Lite, one of their least expensive models.
Prior to this the only commercial grade diffusion model I've encountered is Inception Mercury back in February this year.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0