
























Collaborative Text Editing Without CRDTs or OT
Collaborative Text Editing without CRDTs or OT
Matthew Weidner |
May 21st, 2025
Home | RSS Feed
Keywords: text editing, server reconciliation, Articulated
Collaborative text editing is arguably the hardest feature to implement in a collaborative app. Even if you use a central server and a fully general solution to optimistic local updates (server reconciliation), text editing in particular requires fancy algorithms - specifically, the core of a text-editing CRDT or OT.
Or rather, that’s what I thought until recently. This blog post describes an alternative, straightforward approach to collaborative text editing, without Conflict-free Replicated Data Types (CRDTs) or Operational Transformation (OT). By making text editing flexible and easy to DIY, I hope that the approach will let you create rich collaborative apps that are challenging to build on top of a black-box CRDT/OT library.
This post builds off of my previous post, Architectures for Central Server Collaboration, though I’ll recap ideas as needed to keep it self-contained. In particular, I’ll generally assume that your collaborative app has a central server. A later section extends the approach to decentralized/server-optional collaboration, revealing surprising links to several text-editing CRDTs.
As usual for collaborative text editing, any technique in this post can also be applied to general collaborative lists: ingredients in a recipe, a powerpoint filmstrip, spreadsheet rows and columns, etc.
Sources: I learned the main idea of this approach from a Hacker New comment by Wim Cools from Thymer. It is also used by Jazz’s CoLists. I do not know of an existing public description of the approach - in particular, I have not found it in any paper on crdt.tech - but given its simplicity, others have likely used the approach as well. The extension to decentralized collaboration is based on OpSets: Sequential Specifications for Replicated Datatypes by Martin Kleppmann, Victor B. F. Gomes, Dominic P. Mulligan, and Alastair R. Beresford (2018).
Core Problem
Recap of Architectures for Central Server Collaboration - Challenge: Text and Lists
Let’s start by focusing on one part of the collaborative text editing problem: submitting operations to the server. When a user types a word on their client device, we need to communicate this operation to the server, so that the server can update its own (authoritative) state.
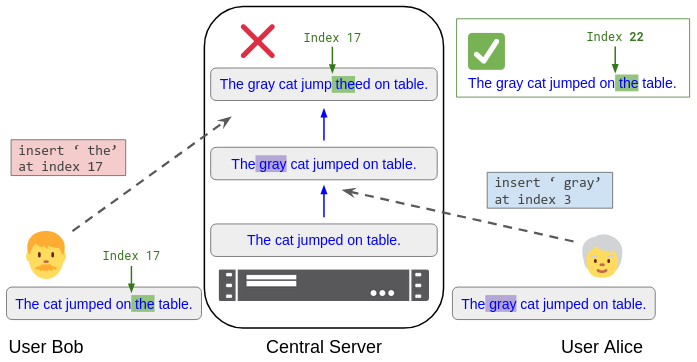
It’s tempting to model the text as an array of characters and send operations to the server that operate on the array representation, like “insert ‘ the’ at index 17”. However, this fails when there are multiple concurrent editors, as shown in Figure 1:
Figure 1. Bob submits the operation "insert ‘ the’ at index 17" to the central server. But before his edit arrives, the server applies Alice's concurrent operation "insert ‘ gray’ at index 3". So it no longer makes sense to apply Bob's operation at index 17; the server must "rebase" it to index 22.
The core problem we must solve is: What operations should clients send to the server, and how should the server interpret them, so that the server updates its own text in the “obvious” correct way?
This “index rebasing” challenge is best known for real-time collaborative apps like Google Docs, but technically, it can also affect non-real-time apps—e.g., a web form that inserts items into a list. The problem can even appear in single-threaded local apps, which need to transform text/list indices for features like inline comments and edit histories.
Issues with Existing Solutions
Existing solutions to this core problem fall into two camps, Conflict-free Replicated Data Types (CRDTs) and Operational Transformation (OT). Roughly:
- CRDTs (2005+) assign an immutable ID (“position”) to each character and sort these IDs using a mathematical total order - often a tree traversal over a special kind of tree.
- OT (1989+) directly “transforms” operations to account for concurrent edits. In the above example, the server’s OT subroutine would transform “insert ‘ the’ at index 17” against “insert ‘ gray’ at index 3”, yielding “insert ‘ the’ at index 22”.
Both CRDT and OT algorithms are used in practice. OT is used by Google Docs; the Yjs CRDT library is used by numerous apps. I’ve personally spent several years thinking and writing about text-editing CRDTs and closely related algorithms. So why does this blog post introduce a different approach, and what makes it better?
The main issue with both CRDTs and OT is their conceptual complexity. Text-editing CRDTs’ total orders are subtle algorithms defined in academic papers, often challenging to read. OT algorithms must satisfy algebraic “transformation properties” that have quadratically many cases and are frequently flawed without formal verification.
Complicated algorithms lead to even more complicated implementations, and CRDT/OT implementations are notoriously difficult. Thus you often use them through libraries, implemented by experts, which you can’t customize without a similar level of expertise. Because collaboration is a full-stack concern, the libraries are also full-stack, taking over core parts of your application: they present as a networked black box that inputs operations and outputs state.
This monolithic, unmodifiable approach becomes a liability when your app requires features that the library author did not anticipate. For example, I would struggle to do any of the following with an existing text-editing CRDT or OT library:
- Divide the state between disk and memory, only loading the necessary parts of a large document.
- Enforce sub-document permissions on the server, e.g., some users are only allowed to edit certain paragraphs or use specific formatting.
- Allow “suggested changes” in the style of Google Docs, either inline or next to the text. (I tried to implement this with my own CRDT library, but got stuck because suggestions could migrate away from their target text - precisely because I had no control over the CRDT’s total order.)
- Store the text in a key-value representation that is easy to sync over an existing key-value store (e.g. Replicache), without merely storing the entire text as a blob or the entire operation history as an array.
- Support operations beyond insert/delete: moving text, document tree manipulations, paragraph splitting/merging, etc.
In contrast, the approach described in this blog post is dead simple. I hope that you will soon understand it well enough to do-it-yourself if you desire. Once that’s done, you can modify the internals and add features at will.
The Approach
Main Idea
The main idea of our approach is straightforward:
- Label each text character with a globally unique ID (e.g., a UUID), so that we can refer to it in a consistent way across time - instead of using an array index that changes constantly. That is, our core data structure has type
Array<{ id: ID; char: string }>. - Clients send the server “insert after” operations that reference an existing ID. E.g., in Figure 1 above, Bob’s operation would be “insert ‘ the’ after
f1bdb70a”, wheref1bdb70ais the ID of ‘n’ in ‘on’. - The server interprets “insert after” operations literally: it looks up the target ID and inserts the new characters immediately after it.
Verify for yourself that this approach would handle both of Figure 1’s edits in the “obvious” correct way.
Some Corrections
You may have noticed two small issues with the above description. Luckily, they are both easy to correct.
First, when Bob sends his operation to the server, he also needs to specify the new elements’ IDs: “insert ‘ the’ after f1bdb70a with ids […]”. In other words, he must tell the server what pairs { id, char } to add to its internal list, instead of just the new characters. (Having Bob generate the IDs, instead of waiting for the server to assign them, lets him reference those IDs in subsequent “insert after” operations before receiving a response to his first operation.)
Second, it’s possible for Bob to send an operation like “insert ‘foo’ after 26085702”, but before his operation reaches the server, another user concurrently deletes the character with ID 26085702. If the server literally deletes its pair { id: "26085702", char: "x" } in response to the concurrent operation, then it won’t know where to insert Bob’s text anymore. The server can work around this by storing IDs in its internal list even after the corresponding characters are deleted: the server’s state becomes a list
Array<{ id: ID; char?: string; isDeleted: boolean }>.
Of course, deleted entries don’t show up in the user-visible text.
In summary, our corrected approach for client -> server communication is as follows:
Client & server text state: Each stores a list of characters labeled by IDs, including deleted IDs.
- Type: `Array<{ id: ID; char?: string; isDeleted: boolean }>`
- Corresponding text: `list.filter(elt => !elt.isDeleted).map(elt => elt.char).join('')`
Typing a character `char`:
1. Client looks up the ID of the character just before the insertion point, `before`.
2. Client generates a globally unique ID for the new character (e.g., a UUID): `id`.
3. Client sends the server the operation: "insert ${char} after ${before} with id ${id}".
4. Server applies this operation to its own state literally:
a. Looks up `before` in its own list, including deleted entries.
b. Inserts `{ id, char, isDeleted: false }` immediately after `before`'s entry in the list.
Deleting a character:
1. Client looks up the ID of the deleted character, `id`.
2. Client sends the server the operation: "delete the entry with id ${id}".
3. Server looks up the entry for `id` and sets `entry.isDeleted = true` if not already.
You probably still have practical concerns with the above approach: e.g., it’s inefficient to store a UUID for every character. I’ll discuss optimizations later.
Client Side
Recap of Architectures for Central Server Collaboration - Server Reconciliation
The approach described so far lets us send operations from clients to the server, updating the server’s state. We managed to solve the core problem in a straightforward way, without combing through any CRDT or OT papers.
For true Google-Docs style collaborative text editing, we also want to let users see the effects of their own operations immediately, without waiting for a response from the server. That is, clients should be allowed to perform optimistic local updates.
Optimistic local updates cause trouble when:
- A client possesses pending local operations - operations that it performed locally but were not yet acknowledged by the server.
- Before receiving an acknowledgment for those operations, the client receives a new remote operation from the server, necessarily concurrent to its pending local operations.
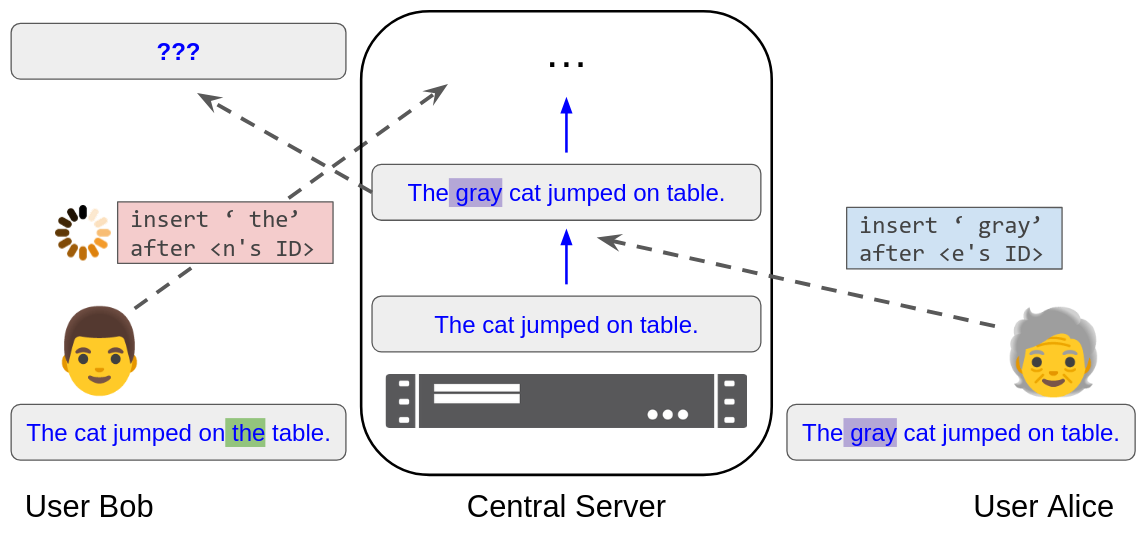
Figure 2. Bob submits the operation "insert ‘ the’ after
At this point, you might say: We have concurrent operations, received in different orders by the client and the server, who must ultimately end up in the same state. Doesn’t that mean we need a CRDT?
Luckily, the answer is no! There is a fully general solution to optimistic local updates, server reconciliation, which is in particular compatible with our “insert after” operations. Briefly, the way you update a client in response to a new remote operation R is:
- Undo all pending local operations. This rewinds the state to the client’s previous view of the server’s state.
- Apply the remote operation(s). This brings the client up-to-date with the server’s state.
- Redo any pending local operations that are still pending, i.e., they were not acknowledged as part of the remote batch.
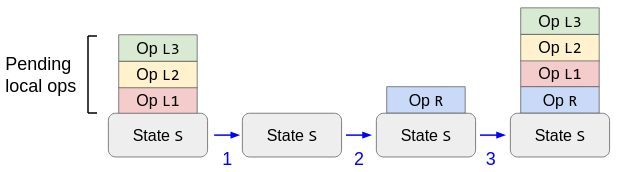
The Server Reconciliation way to process a remote operation R in the presence of pending local operations L1, L2, L3.
There is another strategy that is even simpler than server reconciliation: forbid clients from processing remote operations whenever they possess pending local operations. I learned of this strategy from PowerSync.
For example, in Figure 2, Bob’s client would ignore the first message from the server, instead waiting for the server to process Bob’s message and send the resulting state. Once it receives that state, Bob’s client can directly overwrite its own state. Unless Bob has performed even more operations in the meantime - then his client needs to ignore the server’s second message and wait for a third, etc.
Note that this strategy can led to unbounded delays if Bob types continuously or has high network latency, so it is not as “real-time” as server reconciliation.
Difference from CRDTs
You may object that the above approach sounds a lot like a CRDT. It does share some features: in particular, its assignment of an ID to each character and its use of isDeleted markers (tombstones).
The difference is that our approach handles order in a straightforward and flexible way: clients tell the server to insert X after Y and it does exactly that, or whatever else you program it to do. This contrasts with text-editing CRDTs, in which IDs are ordered for you by a fancy algorithm. That ordering algorithm is what differs between the numerous text-editing CRDTs, and it’s the complicated part of any CRDT paper; we get to avoid it entirely.
Discussion
The previous section described the whole approach in what I hope is enough detail to start implementing it yourself (though first check out Articulated below). Let’s now discuss consequences and extensions of the approach.
Concurrent Insertions
With any collaborative text-editing algorithm, the most interesting theoretical question is: What happens when multiple users type in the same place concurrently?
For example, staring from the text “My name is”, suppose Charlie types “ Charlie”, while concurrently, Dave types “ Dave”. If Charlie’s operation reaches the server first, what is the final text?
Let’s check:
- Charlie’s operation says “insert ‘ Charlie’ after
”. The server processes this literally, giving the text “My name is Charlie”. - Dave’s operation likewise says “insert ‘ Dave’ after
”. The server again processes this literally - inserting after the ‘s’ in ‘is’, irrespective of the concurrent text appearing afterwards - giving the text “My name is Dave Charlie”.
In summary, concurrent insertions at the same place end up in the reverse of the order that the server received their operations. More generally, even without concurrency, insert-after operations with the same target ID end up in reverse order. For example, if Dave typed his name backwards as (e, left arrow, v, left arrow, a, left arrow, D), then each operation would be “insert after Observe that the concurrently-inserted words “ Charlie” and “ Dave” ended up one after the other, instead of becoming interleaved character-by-character (unlike some text-editing CRDTs). That would work even if Charlie and Dave sent each character as a separate operation. Indeed, Dave inserts the ‘a’ in Dave after the ‘D’ (i.e., the insert-after operation references D’s ID), ‘v’ after ‘a’, etc.; so when the server processes these individual operations, it updates its state as
in spite of the unexpected “ Charlie” afterwards.
The same cannot be said for backwards (right-to-left) insertions: if Dave and Charlie both typed their names with copious use of left arrow, and the server received those operations in an interleaved order, then the resulting text would also be interleaved. In practice, this could only happen if Charlie and Dave were both online simultaneously (so that their messages could be interleaved) but stubbornly ignored each other’s in-progress edits.
So far, the only text-editing operations I’ve described are “insert after” and “delete”, which the server applies literally. However, the approach supports many more possible operations. In fact, thanks to our use of server reconciliation, the server has the flexibility to do essentially anything in response to a client operation - clients will eventually end up in the same state regardless. This contrasts with CRDT and OT algorithms, which only allow operations that satisfy strict algebraic rules.
For example, consider the concurrent insertion example from the previous section. The final result, “My name is Dave Charlie”, isn’t very reasonable, even though it satisfies a mathematical specification for collaborative text-editing. A fancy server could do something more intelligent for insertions like Dave’s that are at the same place as a previously-received concurrent insertion. For example:
Clients can also send operations with fancier semantics than “insert after” to better capture user intent - thus increasing the odds that the server’s eventual state is reasonable in spite of concurrent edits. A simple example is “insert before”, the reversed version of “insert after”. E.g., if a user creates a heading above a paragraph, their client could “insert before” the paragraph’s first character, to prevent the header from ending up in the middle of an unrelated addition to the previous paragraph.
Another example is a “fix typo” operation that adds a character to a word only if that word still exists and hasn’t already been fixed. E.g., the client tells the server: “insert ‘u’ after the ‘o’ in ‘color’ that has ID X, but only if the surrounding word is still ‘color’”. That way, if another user deletes ‘color’ before the fix-typo operation reaches the server, you don’t end up with a ‘u’ in the middle of nowhere. (This example avoids an issue brought up by Alex Clemmer).
You can even define operations whose insertion positions change once they reach the server. E.g., the server could handle concurrent insertions at the same position by reordering them to be alphabetical. Or, if you add “move” operations for drag-and-drop, then the server can choose to process “insert after” operations within the moved text in the obvious way - insert them within the moved text instead of at its original location. This contrasts with text-editing CRDTs and my own CRDT-ish libraries (position-strings and list-positions), which fix each character’s position in a global total order as soon as the user types it.
Some of these flexible operations can technically be implemented on top of a CRDT, by having the server initiate its own operations after a client operation (e.g., apply “delete” operations to some text that it wants to ignore). However, I don’t know of CRDT implementations that support “insert before” operations, un-deleting IDs, or changing where an ID ends up in the list.
Rich text enhances plain text with inline formatting (bold, font size, hyperlinks, …), among other features. To handle rich text in our approach, when a user formats a range of text, we of course want to translate the ends of that range into character IDs instead of indices: “apply bold formatting from ID X to ID Y”. (Or perhaps: “apply bold formatting from ID X inclusive to ID Y exclusive”, so that concurrent insertions at the end of the range are also bolded.)
When used alongside a rich-text editor such as ProseMirror, the server can apply such operations literally: look up the current array indices of X and Y, and tell the local ProseMirror state to bold that range of text. ProseMirror will take care of remembering the bold span so that, when the server later receives an insertion within the span, it knows to bold that text too. (Unless the server decides to otherwise, e.g., in response to an operation “insert ‘…’ after ID Z with bold set to false”.)
I believe this simple extension to our approach takes care of the tricky conflict-resolution parts of collaborative rich-text formatting. However, I still recommend reading the Peritext essay for insight into the semantics of collaborative rich-text - what operations clients should send to the server, and how the server should process them.
More info in Architectures for Central Server Collaboration - Appendix: From Centralized to Decentralized
I’ve so far assumed that your app has a central server, which assigns a total order to operations (namely, the order that the server receives them) and updates its authoritative state in response to those operations.
If you don’t have a central server or your app is server-optional, you can instead assign an eventual total order to operations in a decentralized way. For example, order operations using Lamport timestamps. Then treat “the result of processing the operations I’ve received so far in order” as the authoritative state on each client. Our approach’s per-character IDs and “insert after” operations work equally well with this decentralized, “non”-server reconciliation.
Technically, the resulting algorithm is a text-editing CRDT: it’s a decentralized, eventually consistent algorithm for collaborative text editing. I hope that it is easier to understand and implement than a typical text-editing CRDT - it involved no trees or mathematical proofs - and the above remarks on Flexible Operations and Formatting still hold in the decentralized setting.
Nonetheless, you might ask: if “non”-server reconciliation plus our “insert after” operations yields a text-editing CRDT, which CRDT is it? The answer is:
I have not written out a proof of these claims in detail, but I’m happy to discuss my reasoning if you contact me.
Recall that each device’s state in our approach is a list
In practice, you often want to store the actual text elsewhere - e.g., as a ProseMirror state - so our approach really just needs a list
There are a few main tasks that you’ll perform on this list:
A literal array is not great at any of these tasks. Tasks 1-3 take linear time, and the array’s memory and storage space are large - an entire object and UUID per character!
Articulated is a small npm library I made to help out. Its As an added feature, IdList is a persistent data structure. This is great for server reconciliation: each client can cheaply store a copy of the latest state they received from the server alongside their optimistic state, making it trivial to rollback to the server’s last state when they receive a remote operation.
You can check out the docs and (very preliminary) demos to learn more. Or, read through the code for IdListSimple - it’s a simple, < 300 SLOC implementation of IdList that omits its optimizations and persistence but is otherwise functionally identical (verified by fuzz tests).
I hope that, within the context of a server reconciliation architecture, Articulated can serve a similar purpose to an optimized CRDT library, but with the flexibility and other advantages described in this blog post.
Home
• Matthew Weidner
• Common Curriculum / CMU PhD student
• mweidner037 [at] gmail.com
• @MatthewWeidner3
• @mweidner.bsky.social
• LinkedIn
• GitHub
"My name is D Charlie" -> "My name is Da Charlie"
-> "My name is Dav Charlie" -> "My name is Dave Charlie"
Flexible Operations
Formatting (Rich Text)
Decentralized Variants
Helper Library: Articulated
Array<{ id: ID; char?: string; isDeleted: boolean }>;
Array<{ id: ID; isDeleted: boolean }>;
IdList data structure provides the same functionality as the above array, but with optimizations similar to those in popular text-editing CRDT libraries:
{ bunchId, counter }, where bunchId is a UUID that can be shared between a “bunch” of IDs with varying counter. When IDs in a bunch appear alongside each other - e.g., in the common case of left-to-right insertions - IdList stores them as a single object in memory and in the serialized state.log or log^2 time method calls.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0