





























Build your own Siri locally and on-device

The edge is back. This time, it speaks.
Let’s be honest.
Talking to ChatGPT is fun.
But do you really want to send your "lock my screen" or "write a new note” request to a giant cloud model?
…Just to have it call back an API you wrote?
🤯 What if the model just lived on your device?
What if it understood you, called your functions directly, and respected your privacy?
We live in an era where everything is solved with foundational LLM APIs, privacy is a forgotten concept, and everybody is hyped about any new model. However, nobody discusses how that model can be served, how the price will scale, and how data privacy is respected.
It’s all noise.
Experts everywhere.
And yet... no one shows you how to deliver something real.
That’s why ML Vanguards exists.
We’re done with generic AI advice.
Done with writing for engagement metrics.
Done with pretending open-source LLMs are production-ready "out of the box."
We’re here to build.
Only micro-niche, AI-powered MVPs.
Only stuff that runs. In prod. Locally. Privately.
Imagine this:
You’re in a meeting. You whisper:
“Turn off my volume. Search when the thermal motor was invented.”
Your laptop obeys.
No API call to the cloud.
No OpenAI logs.
Just you, a speech-to-text model, a lightweight LLM, and a bit of voice magic.
What if Siri lived on your machine?
This isn’t sci-fi.
It’s actually easier than ever to build your own local voice assistant that:
Understands natural language
Executes your own app functions
Works offline on macOS, Linux, and even mobile
Keeps all data private, stored on your deivce
I’m building this and’ll teach you how to do it too.
Who is this for?
This isn’t for chatbot tinkerers.
This is for:
Devs building on the edge
Privacy-first mobile apps
Teams deploying apps in sensitive environments (health, legal, internal tools)
R&D teams passionate about on-device AI

What’s in this mini-course?
This 5-part hands-on series is 100% FREE.
In this hands-on course, you'll:
Fine-tune LLaMA 3.1 8B with LoRA for local use
Create a function-calling dataset (like https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k)
Run inference locally on your laptop using GGUF
Connect everything to voice input/output (with Whisper or other custom model for speech-to-text)
Oh, it also has a GitHub repository!
Part 1: The architecture (today's lesson)
Why is now the time to run voice assistants locally? Complete system overview with function mapping.
Part 2: Building the dataset
We’ll generate a custom function that calls the dataset using prompt templates, real API call formats, and verification logic.
Part 3: Fine-Tuning for function calling
You’ll learn how to fine-tune LLaMA 3.1 (or TinyLlama) using Unsloth, track it with W&B, and export as a GGUF model for edge inference.
Part 4: Speech-to-action pipeline
We’ll use Whisper (tiny model) to transcribe speech, send it through the LLM, parse the response, and call the actual function on-device.
Part 5: Packaging the agent (TBD)
Final UX polish: make it a menubar app on Mac, a background service on Linux, or integrate it into your mobile app.
🚀 Want to follow along, or build your own?
📩 Subscribe to the series
🔧 Need help building one? Book a free strategy call
Let’s make local AI useful again.
Let’s build something that works.
Part 1: The architecture & MLOPs
Why is MLOPs still relevant even if the system is running on the device and it’s private?
🧩 The System Overview
Before we get excited about whispering to our laptops/mobiles and running function calls on-device, we need to pause and ask:
“Where in my system can things go wrong and impact the user?”
That’s the heart of MLOps. And even if this is a “local-only, no-cloud” assistant, the principles still apply.
Here’s why:
Models drift — even locally. If you fine-tune, you need to track it.
Prompt engineering is messy — your logic might change weekly.
Debugging hallucinations? Good luck without logs or prompt versions.
Dataset validation? — how do we really know that dataset we’ve just created is good enough?
Evaluation the fine-tuned model
Let’s not forget that the building part of this system is happening on the cloud. Building the dataset, fine-tuning the model, deploy the model the model to a model registry
The irony of building an “on-device Siri” is that… it starts online.
Not cloud-based inference — but online development.
This is the part where MLOps earns its name.
The online phase
When you build a voice assistant that runs locally, you still need:
A fine-tuning dataset with function-calling principles in mind
A testing suite for common interactions
An evaluation strategy for real-world usage
Custom dataset creation
This is the first place people cut corners. They scrape a few prompts, convert them into JSON, and call it a dataset. Then they fine-tune, and wonder why the model breaks on anything slightly off-pattern.
A better approach is to version the dataset, test multiple edge cases, and label failure modes clearly. Ask:
How diverse are your command phrasings?
Do you include rare or ambiguous intents?
Do you cover common errors like repetitions, hesitations, or mic glitches?
Fine-tuning
Fine-tuning is deceptively simple. It works. Until it doesn’t.
The model improves on your examples — but gets worse everywhere else.
This is where experiment tracking matters. Use simple MLOps principles like:
Version every checkpoint
Test on unseen commands, not just your eval set
Compare against your zero-shot baseline
And most importantly, validate the hybrid system — LLM + function caller + speech parser — not just the LLM alone.
Testing the whole system
You don’t ship a local agent before stress-testing it. Build a script that runs through:
100+ common voice commands
Wrong mic inputs
Conflicting functions
Empty or partial user phrases
Multiple accents and speech patterns (if you use Whisper or STT)
Catch regressions before you put the model on-device.
The offline phase
This is where people relax. Don’t.
Deploying a model offline doesn’t mean it’s safe from bugs. It means you lose visibility.
So the only way to survive this phase is to prepare for it:
Run your system on multiple devices, with different specs and OS versions
Use test users (not just friends) and ask them to break it
Track logs locally and offer a way for testers to export logs manually (opt-in)
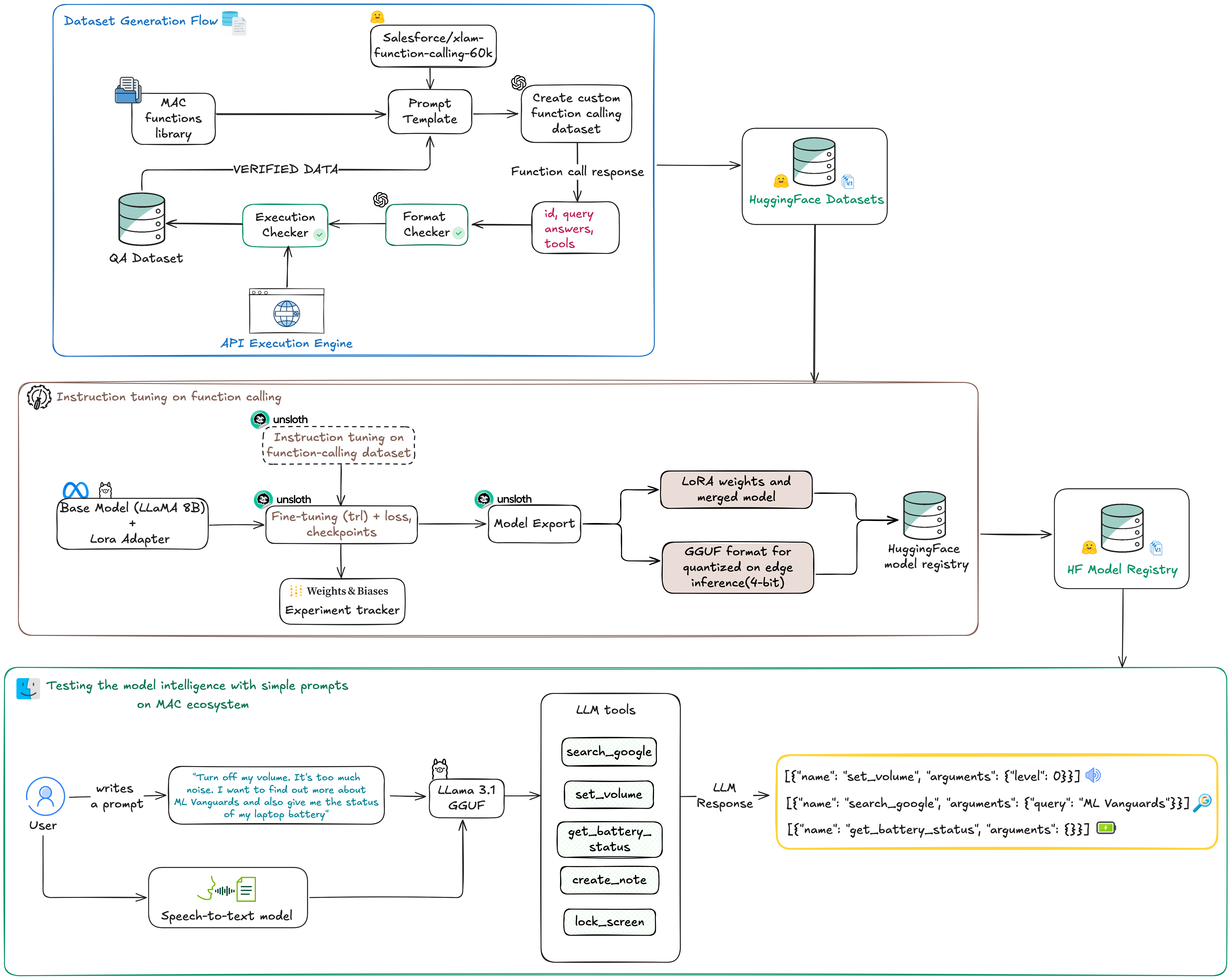
Here’s the system in 3 major phases:
1. Dataset Generation Flow
Before we can train a model to call functions like lock_screen() or search_google("ML Vanguards"), we need to teach it how those calls look in a natural conversation. This part handles:
Building a dataset using prompts and LLMs
Using templates to simulate human-like voice requests, simulating different core functions of your system
Automatically verifying outputs with a test engine
Creating a clean dataset for function-calling fine-tuning
This is the most overlooked part in most LLM tutorials: how do you teach a model to behave in your context? Not by downloading alpaca data. You have to create your own, structured, specific, and validated.
We don’t want “chatbot vibes.” We want deterministic, parseable function calls from real intent.
2. Instruction Tuning for Function Calling
Once we have the dataset, we fine-tune a small base model (like LLaMA 3.1 8B) using LoRA adapters. The goal is not general reasoning, it’s precision on our task: map spoken intent to exact API calls.
We use:
Unsloth for fast, GPU-efficient fine-tuning
Supervised instruction tuning (SFT) with a custom loss
Weights & Biases to track experiments
Export to GGUF for 4-bit quantized inference
This step allows us to deploy the model efficiently on consumer hardware, laptops, phones, even Raspberry PIs (will be a BONUS chapter about this) , without needing a GPU at inference time.
3. Testing the Model in the MAC Ecosystem
The final piece ties it all together. We connect:
Whisper for speech-to-text
Our fine-tuned LLM for function parsing
A small toolset of real functions:
lock_screen(),get_battery_status(), etc.
The result? A working agent that:
Listens to your voice
Converts it into structured function calls
Executes them on your machine
Does all of this without touching the cloud
This system can run in real time, without network access, with full control and observability.
What’s next?
Building AI systems that run locally doesn’t mean leaving rigor. In fact, it demands more of it.
You don’t have the fallback of logging everything to some remote server. You can’t ship half-baked models and patch them later with “just a new prompt.” Once it’s on-device, it’s on you.
So we start with MLOps. Not dashboards. Not tooling. Just a thinking framework:
How do we avoid silent failures?
How do we make changes traceable?
How do we catch issues before the user does?
This first lesson was about that thinking process. The invisible part that makes everything else possible. And we will see in the next lessons how we will apply those MLOPS principles to each component.
Next up: how to actually generate the function-calling dataset.
We’ll write prompts, simulate user requests, auto-verify outputs, and build the data we need to fine-tune the model. No scraping. Just structured, validated data that teaches the model how to behave.
Want the next part?
Subscribe to follow the series as it drops.
🧠 Need help designing your own local AI system?
Book a call— we help R&D teams and startups ship real, on-device products.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0








