































Getting AI to write good SQL

Organizations depend on fast and accurate data-driven insights to make decisions, and SQL is at the core of how they access that data. With Gemini, Google can generate SQL directly from natural language — a.k.a. text-to-SQL. This capability increases developer and analysts’ productivity and empowers non-technical users to interact directly with the data they need.
Today, you can find text-to-SQL capabilities in many Google Cloud products:
-
BigQuery Studio in the SQL Editor and SQL Generation tool, and within the Data Canvas SQL node
-
"Help me code" functionality in Cloud SQL Studio (Postgres, MySQL and SQLServer), AlloyDB Studio and Cloud Spanner Studio
-
AlloyDB AI with its direct natural language interface to the database, currently available as a public preview
-
Through Vertex AI, which lets you access the Gemini models that are the basis for these products directly
Recently, powerful large language models (LLMs) like Gemini, with their abilities to reason and synthesize, have driven remarkable advancements in the field of text-to-SQL. In this blog post, the first entry in a series, we explore the technical internals of Google Cloud's text-to-SQL agents. We will cover state-of-the-art approaches to context building and table retrieval, how to do effective evaluation of text-to-SQL quality with LLM-as-a-judge techniques, the best approaches to LLM prompting and post-processing, and how we approach techniques that allows the system to offer virtually certified correct answers.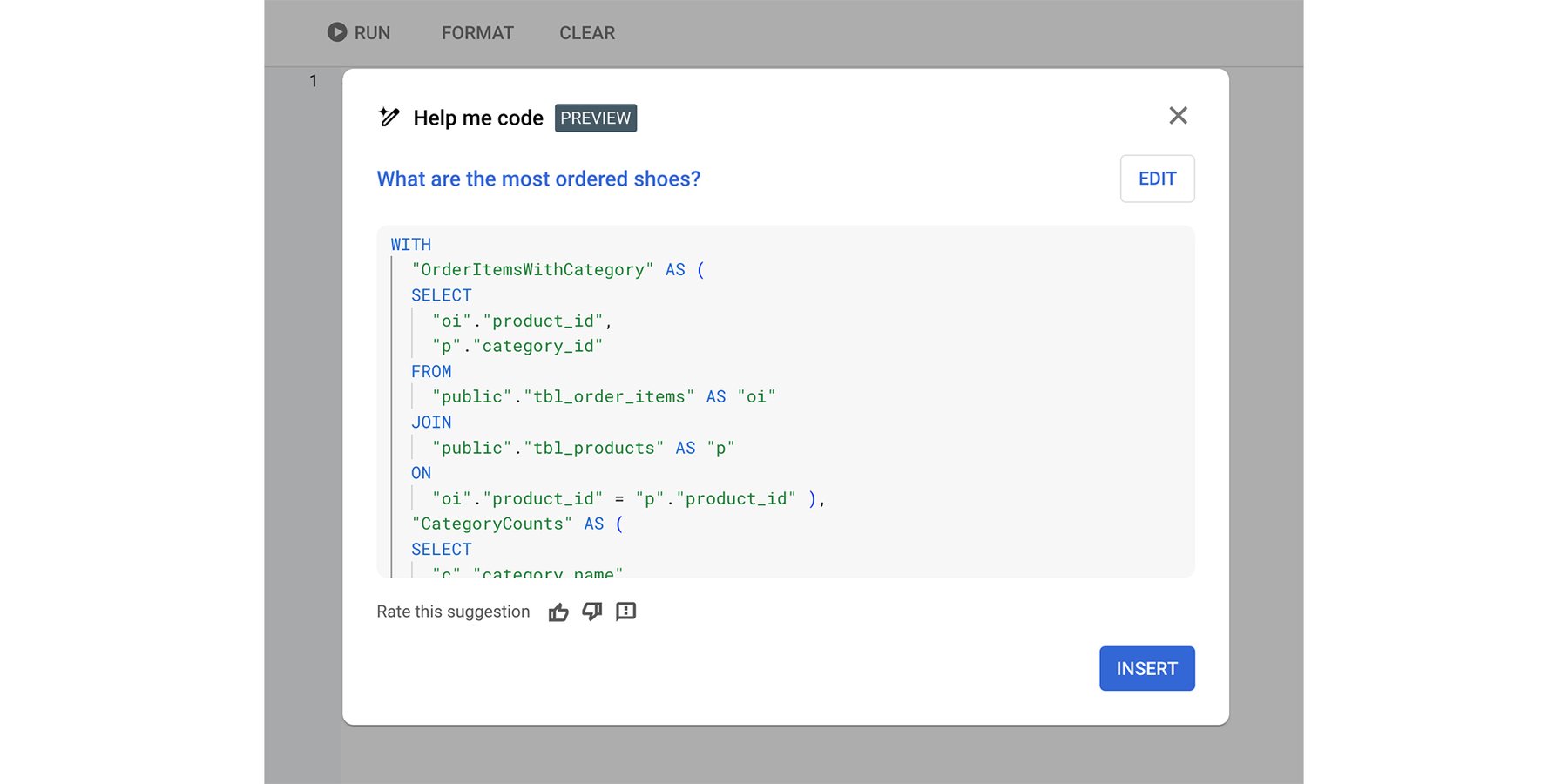
The ‘Help me code’ feature in Cloud SQL Studio generates SQL from a text prompt
The challenges of text-to-SQL technology
Current state-of-the-art LLMs like Gemini 2.5 have reasoning capabilities that make them good at translating complex questions posed in natural language to functioning SQL, complete with joins, filters, aggregations and other difficult concepts.
To see this in action you can do a simple test in Vertex AI Studio. Given the prompt "I have a database schema that contains products and orders. Write a SQL query that shows the number of orders for shoes", Gemini produces SQL for a hypothetical schema:
Great, this is a good looking query. But what happens when you move beyond this trivial example, and use Gemini for text-to-SQL against a real world database and on real-world user questions? It turns out that the problem is more difficult. The model needs to be complemented with methods to:
-
provide business-specific context
-
understand user intent
-
manage differences in SQL dialects
Let’s take a look at each of these challenges.
Problem #1: Provide business-specific context
Just like data analysts or engineers, LLMs need significant amounts of knowledge or "context" to generate accurate SQL. The context can be both explicit (what does the schema look like, what are the relevant columns, and what does the data itself look like?) or more implicit (what is the precise semantic meaning of a piece of data? what does it mean for the specific business case?).
Specialized model training, or fine tuning, is typically not a scalable solution to this problem. Training on the shape of every database or dataset, and keeping up with schema or data changes, is both difficult and cost-prohibitive. Business knowledge and semantics are often not well documented in the first place, and difficult to turn into training data.
For example, even the best DBA in the world would not be able to write an accurate query to track shoe sales if they didn't know that cat_id2 = 'Footwear' in a pcat_extension table means that the product in question is a kind of shoe. The same is true for LLMs.
Problem #2: Understanding user intent
Natural language is less precise than SQL. An engineer or analyst faced with an ambiguous question can detect that they need more information and go back and ask the right follow-up questions. An LLM, on the other hand, tends to try to give you an answer, and when the question is ambiguous, can be prone to hallucinating.
Example: Take a question like "What are the best-selling shoes?" Here, one obvious point of ambiguity is what "best selling" actually means in the context of the business or application — the most ordered shoes? The shoe brand that brought in the most money? Further, should the SQL count returned orders? And how many kinds of shoes do you want to see in the report? etc.
Further, different users need different kinds of answers. If the user is a technical analyst or a developer asking a vague question, giving them a reasonable, but perhaps not 100% correct SQL query is a good starting point. On the other hand, if the user is less technical and does not understand SQL, providing precise, correct SQL is more important. Being able to reply with follow-up questions to disambiguate, explaining the reasoning that went into an answer, and guiding the user to what they are looking for is key.
Problem #3: Limits of LLM generation
Out of the box, LLMs are particularly good at tasks like creative writing, summarizing or extracting information from documents. But some models can struggle with following precise instructions and getting details exactly right, particularly when it comes to more obscure SQL features. To be able to produce correct SQL, the LLM needs to adhere closely to what can often turn into complex specifications.
Example: Consider the differences between SQL dialects, which are more subtle than differences between programming languages like Python and Java. As a simple example, if you're using BigQuery SQL, the correct function for extracting a month from a timestamp column is EXTRACT(MONTH FROM timestamp_column). But if you are using MySQL, you use MONTH(timestamp_column).
Text-to-SQL techniques
At Google Cloud, we’re constantly evolving our text-to-SQL agents to improve their quality. To address the problems listed above, we apply a number of techniques.
|
Problem |
Solutions |
|
Understanding schema, data and business concepts |
|
|
Understanding user intent |
Disambiguation using LLMs
SQL-aware foundation models |
|
Limits of LLM generation |
Self-consistency Validation and rewriting
|
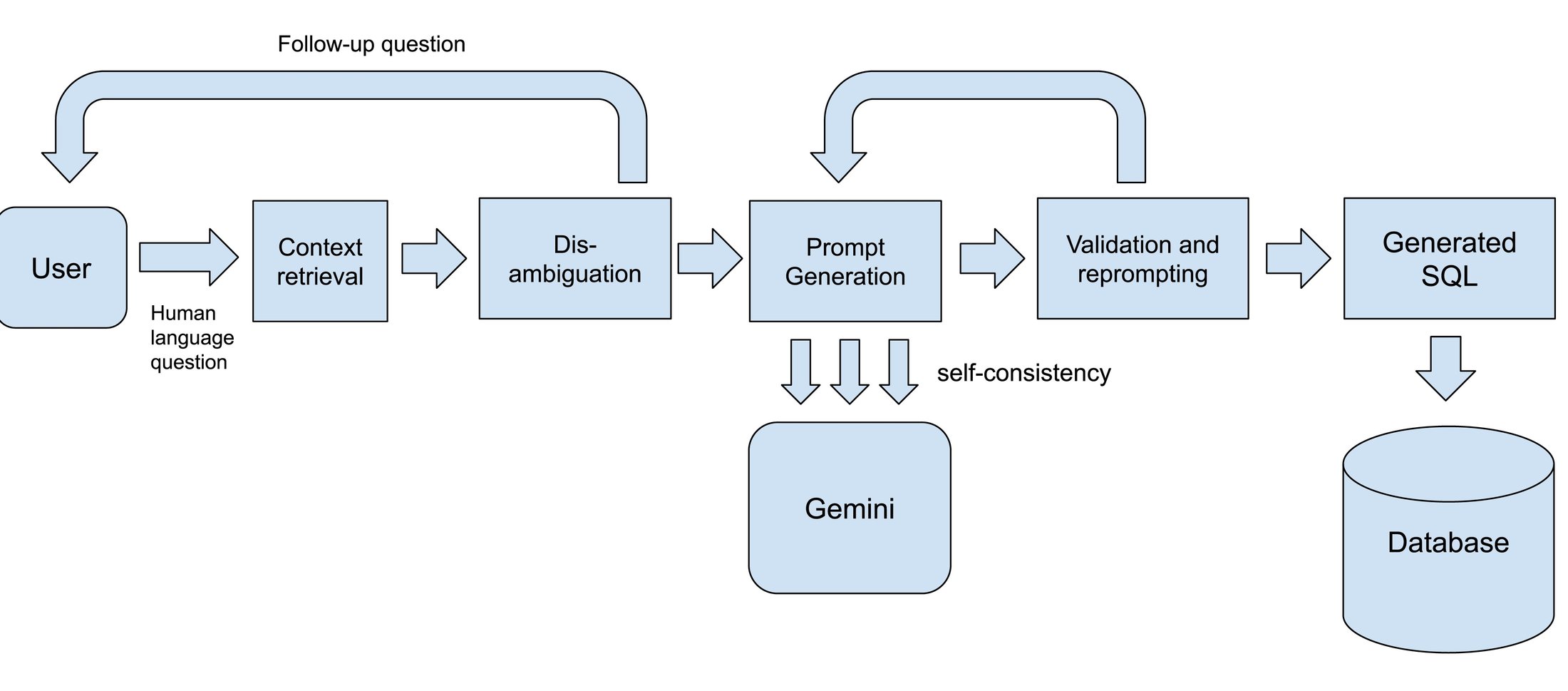
The text-to-SQL architecture
Let’s take a closer look at some of these techniques.
SQL-aware models
Strong LLMs are the foundation of text-to-SQL solutions, and the Gemini family of models has a proven track record of high-quality code and SQL generation. Depending on the particular SQL generation task, we mix and match model versions, including some cases where we employ customized fine-tuning, for example to ensure that models provide sufficiently good SQL for certain dialects.
Disambiguation using LLMs
Disambiguation involves getting the system to respond with a clarifying question when faced with a question that is not clear enough (in the example above of "What is the best selling shoe?" should lead to a follow-up question like "Would you like to see the shoes ordered by order quantity or revenue?" from the text-to-SQL agent). Here we typically orchestrate LLM calls to first try to identify if a question can actually be answered given the available schema and data, and if not, to generate the necessary follow-up questions to clarify the user's intent.
Retrieval and in-context-learning
As mentioned above, providing models with the context they need to generate SQL is critical. We use a variety of indexing and retrieval techniques — first to identify relevant datasets, tables and columns, typically using vector search for multi-stage semantic matching, then to load additional useful context. Depending on the product, this may include things like user-provided schema annotations, examples of similar SQL or how to apply specific business rules, or samples of recent queries that a user has run against the same datasets. All of this data is organized into prompts then passed to the model. Gemini's support for long context windows unlocks new capabilities here by allowing the model to handle large schemas and other contextual information.
Validation and reprompting
Even with a high-quality model, there is still some level of non-determinism or unpredictability involved in LLM-driven SQL generation. To address this we have found that non-AI approaches like query parsing or doing a dry run of the generated SQL complements model-based workflows well. We can get a clear, deterministic signal if the LLM has missed something crucial, which we then pass back to the model for a second pass. When provided an example of a mistake and some guidance, models can typically address what they got wrong.
Self-consistency
The idea of self-consistency is to not depend on a single round of generation, but to generate multiple queries for the same user question, potentially using different prompting techniques or model variants, and picking the best one from all candidates. If several models agree that one answer looks particularly good, there is a greater chance that the final SQL query will be accurate and matches what the user is looking for.
Evaluation and measuring improvements
Improving AI-driven capabilities depends on robust evaluation. The text-to-SQL benchmarks developed in the academic community, like the popular BIRD-bench, have been a very useful baseline to understand model and end-to-end system performance. However, these benchmarks are often lacking when it comes to representing broad real-world schemas and workloads. To address this we have developed our own suite of synthetic benchmarks that augment the baseline in many ways.
Coverage: We make sure to have benchmarks that cover a broad list of SQL engines and products, both dialects and engine-specific features. This includes not only queries, but also DDL, DML and other administrative needs, and questions that are representative for common usage patterns, including more complex queries and schemas.
Metrics: We combine user metrics and offline eval metrics, and employ both human and automated evaluation, particularly using LLM-as-a-judge techniques, which reduce cost but still allow us to understand performance on ambiguous and unclear tasks.
Continuous evals: Our engineering and research teams use evals to quickly be able to test out new models, new prompting techniques and other improvements. It can give us signals quickly to tell if an approach is showing promise and is worth pursuing.
Taken together, using these techniques are driving the remarkable improvements in text-to-SQL that we are witnessing in our labs, as well as in customers’ environments. As you get ready to incorporate text-to-SQL in your own environments, stay tuned for more deep dives into our text-to-SQL solutions. Try Gemini text-to-SQL in BigQuery Studio, CloudSQL, AlloyDB and Spanner Studio, and in AlloyDB AI today.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0









