




























The Unreasonable Effectiveness of Fuzzing for Porting Programs

The Unreasonable Effectiveness of Fuzzing for Porting Programs
A simple strategy of having LLMs write fuzz tests and build up a port in topological order seems effective at automating porting from C to Rust.
Agents are starting to produce more and more code
A week or 2 back, I was reflecting on some code Claude had generated for me and I had a sort of moment of clarity. "Clarity" might be overstating it; more like the type of thought you have in the shower or after a few beers. Anyway.
The thought was: LLMs produce more and more code, and they'll eventually be producing more code than people. We can imagine at some point we're going to fork from mostly people writing code to mostly computers. What does this mean for how we're going to treat our libraries and code maintenance in the future?
LLMs make it easier to deal with API issues or inconsistencies, they're dealing with it, not us. Will this continue, leaving us with a The Princess and the Pea situation where we deal with piles of leaking abstractions? Or will we use LLMs to radically change our APIs when needed - will things get cleaner and better and faster as we go?
LLMs open up the door to performing radical updates that we'd never really consider in the past. We can port our libraries from one language to another. We can change our APIs to fix issues, and give downstream users an LLM prompt to migrate over to the new version automatically, instead of rewriting their code themselves. We can make massive internal refactorings. These are types of tasks that in the past, rightly, a senior engineer would reject in a project until its the last possibly option. Breaking customers almost never pays off, and its hard to justify refactoring on a "maintenance mode" project.
But if its more about finding the right prompt and letting an LLM do the work, maybe that changes our decision process.
Maintaining big important libraries is no fun
I used to work on TensorFlow. (TensorFlow is a system to develop gradient based models, like PyTorch. It's not used so much anymore outside of Google.) Now TensorFlow had some design flaws in the core language, and a botched version 1 -> version 2 migration didn't help matters too much. But as a maintainer, the biggest issue was the enormous technical debt. It suffered from a sort of "career advancement syndrome" I sadly missed this period and only was around for the aftermath where we had to deal with the cruft. : TensorFlow was popular and you got credit for contributing to it, so there was a huge incentive to add some feature as quickly as you could and then get away.
As a result of a few years of this style of development, a huge surface of Python code had been cobbled together on top of the C++ core. The complexity only spiraled over time: engineers came into the project and needed to get something done. Increasingly the easiest thing to do was to add some Python global or context manager, shove something in it, then grab it later. Do this over and over and eventually it becomes impossibly to figure out what's happening. It also ended up being incredibly slow. It would take 10s of minutes to build some graphs (TensorFlow's equivalent of a program).
As a result of this over time TensorFlow became harder and harder to maintain, much less evolve It was also hard to keep good engineers working on the project. If you're a good engineer, other teams want you and you could choose to work on less crufty, more exciting projects like Jax or XLA, or you know, Ads. . One idea we discussed internally to try to fix this was porting the Python code, bit by bit, into a more comprehensible C++ layer, and then re-exporting it via PyBind. At first you'd still call everything through the Python interface, but as you ported code over, you could start to use the internal C++ interfaces more and more, getting faster and more stable as you went. This would incrementally improve the performance and consistency of the system, or that was the hope.
But it would have been an enormous effort to do this all. Each time you tried to port a module you'd reveal subtle errors or assumptions that you'd need to debug and revisit, update users etc. Given our staffing, we couldn't really justify the time versus the real work of making sure Ads didn't break.
Even though TensorFlow was moving to maintenance mode, if we could have made this type of change it would have improved the maintainer and users' experience for the years we need to keep the lights on. But because the cleanup was thorny and slow, we just couldn't justify the cost.
This is by no means limited to TensorFlow. If you're working on something like libexpat its hard to justify refactoring your code or rewriting it in Rust, no matter how potentially useful it would be, when you've got this at the top of your page:
But what if we could make this type of refactoring much, much cheaper?
Infinite patience versus really hard problems
My experience with coding agents like Claude Code and Aider makes me think this could be different today. I've found that agents are really good when you set them up against a concrete obstacle: "I changed this API, now fix everything until the tests pass". They can show real ingenuity in finding solutions to subtle problems. I've had the LLM diagnose subtle bugs in a program, write test cases, write minimizers, and probe for solutions, where my contribution to this conversation largely consisted of "keep going until the test passes". Not always, of course. Good luck getting an agent to produce anything other than React & Tailwind on your new project, for instance.
My hunch is that the stronger the test case, the more concrete the objective the LLM has to fulfill, the less likely it is to try to sabotage the problem. e.g. "I made an empty test and it passed", or to misinterpret the request "you asked for a Ruby on Rails project, so here's NextJS, like you asked for".
You're putting the agent between a rock and a hard place, as it were, and this reduces the easy solutions it could use, and thus it works harder to find a real solution.
In general its really hard to define test cases, a priori, that are specific enough to constrain the LLM to do exactly what you want. But what about when we're changing an existing project? What if we could constrain the output before and after the changes to be the same? This could be as simple as running all of our tests for our project, if we're confident they're very thorough. For most complex changes, it might be hard to keep both versions aligned.
What happens if we take a very specific and important type of refactoring: moving from an unsafe language like C to a safe language like Rust? "I did something with memory I shouldn't have" are still in the top 3 for CVEsNo longer #1, not because the number of memory CVEs is going down, but because XSS vulnerabilities have grown so quickly 🤦. . This is exactly the type of thing we might like to do, but hard to justify. Can we make porting more of a prompt engineering problem instead of a coding one? Let's find out...
Going from C to Rust
Porting C to Rust with LLMs isn't a brand new idea: c2rust can produce a mechanical translation of C code to Rust, though the result is intentionally "C in Rust syntax", with the idea that a person uses it as a starting point to then Rustify the project.
More recently researchers have started throwing LLMs at the problem. Syzygy is the only paper I found which produced a complete working implementation of a library, the other papers were more like "we threw this at the wall and it compiled". Syzygy leverages a bunch of machinery to mechanize parts of the porting process:
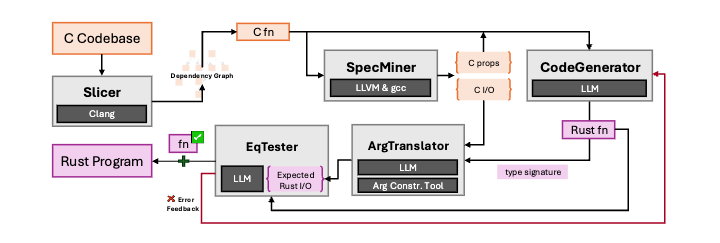
What's cool is their approach works: they get a compression program out of it, and its all safe Rust. That's a non-trivial achievement! That said, it runs 3x slower than the C version, and its not identical: how much this detail matters depends on the users of your API and how much you care about Hyrum's Law.
Syzygy puts a lot of work into developing test cases for symbols as they port, but because the tests are against inferred properties of the C program, instead of directly comparing against the C behavior, you can end up with subtle changes in behavior. This is hard to avoid with their approach: if the interfaces differ, it becomes hard to perform a direct comparison between your C and Rust programs.
I wanted to test if we could do something radically simpler and more direct: what if we just randomly compared the C and Rust output as we ported? Would that be sufficient to port an entire library? Or would our tests be ineffectual and we'd get stuck halfway through. In effect we'd be performing a specific type of fuzz or property testing to our program as we ported it.
Property testing
Property testing has an interesting supposition: we can avoid the drudge work of writing tests by having the computer build out the test cases for us, and just check if a property holds for our system. Trivia item: it is a fundamental law of all property testing frameworks that they start with one of 2 examples:
- reverse is its own inverse, so
x = reverse(reverse(x)). - the elements of a sorted list are in order
Don't believe me? Check it out:
These examples are common for a reason. They're the perfect fit for property testing: you just feed random lists in and check your condition holds. A common critique of property testing is that it doesn't really extend beyond these examples. Either its too hard to generate meaningful inputs, or properties to test, and so we're better off writing individual test cases. My experience is that there's some narrow cases where property testing is great, but I still end up writing plenty of individual tests.
Sometimes determining the property that holds is hard: I can test individual cases and validate them, but I don't know how to generalize. Or generating interesting inputs might be hard. If I want to test a C parser, sampling random bit strings isn't going to help me very much. Entire projects like Csmith are dedicated to fuzzing C compilers.
But in our case we've solved at least the property test is solved for us: we have the perfect output property to test: for a given input X, does our Rust library produce the exact same output as our C library? If we can test this over an interesting part of our input space, then we can be confident we've preserved our behavior.
Let's see how this works out.
Porting C to Rust, attempt 0
The logs of my first attempt are fortunately lost to the howling void. I spent an hour or 2 with Claude Code, following this policy:
- Port symbol X
- Write a test for symbol X to make sure it works
I wasn't comparing directly against the C version, instead relying on the unit tests
to validate the behavior was preserved. This attempt did not go well. As modules
were ported over, and we started to use symbols from previous ports, we exposed
more and more latent bugs. Eventually, you're in a state where the top-level
ZopfliCompress doesn't work, and you're stuck debugging the whole program to
figure out what happened.
I realized this wasn't going to scale. Even if I got something working, I was looking at a lot of work and I couldn't explain how to replicate what I did with another project.
Porting C to Rust, attempt 1
My firstsecond attempt was truly slightly less crude:
- For each C module, ask Claude Code to write a Rust version.
- Then write a fuzz test for that module
The results of this experiment are on Github.
This time, it worked: other than writing the porting guidelines and cajoling the model, I didn't do much work. I didn't do any debugging by hand or have to intercede to understand what was happening. In the case a test found a discrepancy, I would have the model write a bug report and then iterate until it solved the problem.
But again this wasn't automated and it was hardly reproducible. I had to babysit
the process quite a bitMostly telling it to keep going. I probably could have written while true; echo 'keep going until the test passes' | claude and gotten most of the way there. , and while the library seemed to work, the
results were subtly different than the original Zopfli C implementation. And
because of the ad-hoc approach, I didn't have a good idea of what had changed.
Still this was promising. So I was incentivized to try again, with a bit more rigor and automation.
Porting C to Rust, "for real"
Our final process would be more rigorous. We want to port a small portion of our program at a time, and automate as much of the porting as possibly. Instead of calling into an agent and babysitting it, we'd need to hand-roll our own machinery to call into an LLM API and perform the necessary edits in a fully automated fashion. So our overall process would be:
-
Sort symbols in topological order based on the static call graph. If function F calls function G, then first port function G, then function F, etc. (Cycles need to be ported together, but we didn't have any for this library). This ensures that when we are porting a new symbol into Rust, we can call into our child symbols immediately; we don't have to implement anything new or call into C. "Symbol" here means a struct, enum or function.
-
For a given public C declaration (in a header file), create an FFI entry for it and a Rust implementation with the exact same signature. We'll do this by giving the LLM the C header & source and asking for a translation.
// ffi.rs
pub fn AddDynamicTree(
ll_lengths: *const ::std::os::raw::c_uint,
d_lengths: *const ::std::os::raw::c_uint,
bp: *mut ::std::os::raw::c_uchar,
out: *mut *mut ::std::os::raw::c_uchar,
outsize: *mut usize,
);
// deflate.rs
pub unsafe fn AddDynamicTree(
ll_lengths: *const c_uint,
d_lengths: *const c_uint,
bp: *mut c_uchar,
out: *mut *mut c_uchar,
outsize: *mut usize,
) {
...
}
- Have the LLM write a fuzz test which samples over possibly inputs and compares the C and Rust implementations, asserting if there is a discrepancy example. No attempt was made to guide the fuzz test inputs other than instructing the LLM to avoid generating invalid structures (e.g. null pointers or numbers out of an expected range).
#[derive(Debug, arbitrary::Arbitrary)]
struct FuzzInput {
ll_lengths: Vec,
d_lengths: Vec,
}
fuzz_target!(|input: FuzzInput| {
...
// setup inputs
let c_result = ffi::AddDynamicTree(...)
let rust_result = rust::AddDynamicTree(...)
assert_eq!(c_result, rust_result, "C and Rust diverged.");
- Run the fuzz test and fix until everything compiles and the fuzz test passes.
We repeat this for each symbol in the program until we hit the top-level main().
Prior to porting I modified the C source slightly to make a few static functions
extern so that we could create an FFI to them. This would allow the LLM to port
smaller chunks at a time (otherwise there were some modules where the LLM would
have to port 1000 lines of code at once because only the main symbol was
visible). I also copied some #define constants by hand because my C traversal
hadn't detected them.
Originally I tried to break up the task of porting a symbol. We'd separately define the FFI to C, a stub implementation of the Rust function, define a fuzz test, then build the implementation. The idea was that this would let us verify each of these via a separate call and we'd be more robust. Ultimately this proved more confusing to the agents than helpful.
In the end, I simply prompted the LLM to do all the steps for porting a symbol at once, reprompting it if the fuzz test didn't exist or pass.
And in the end... it worked? The result is a Rust implementation of Zopfli that gives identical results on every input I've tried to the C version. This is different from the Syzygy results, where they ended up with a program that compresses correctly, but not identically This isn't a claim my approach is better than Syzygy, just different. to the C version. Because we locked the Rust and C versions to use the same API at each step, the resulting program isn't very "rusty", but its a complete translation.
About 90% of symbols were auto-ported using gemini-2.5-pro-06-05 and a crappy "agent" library I wrote up for this task. The remaining 10% I switched over to running in a Claude Code, as Gemini seemed to struggle with patch formats and imports. The only work I did manually was to adjust a few places where the LLM was calling the FFI code from Rust and clean up some warning messages.
But why does this work at all?
To clarify, the surprising result is not that fuzzing would detect discrepancies at the top-level of our library. Target specific fuzzers work great for this task: CSmith and Jepsen find all sorts of weird interesting bugs. What's surprising is that with only one exceptionGemini introduces a weird typo into a program, which was detected a few symbols downstream by Claude and repaired. You can see the session log here. , the LLM translation + naive fuzz test correctly validated the symbol behavior for every symbol. This meant that we didn't run into any issues where after porting A, B ... Q, suddenly we detect a subtle bug in R.
This meant we didn't have to "backtrack", or inspect the rest of the code base as we ported symbols: each symbol ported in isolation, we tested it (implicitly testing the dependent symbols as well), and we moved on. If this didn't work, we'd have to inspect the whole program and debug it, over and over, as we built it up.
If we think about it, this shouldn't have worked as well as it did. Fuzzing shouldn't hold for all functions. Imagine I'm converting something like a manual floating-point multiplier:
mul(a_bits: &[byte], b_bits: &[byte], c_bits: mut &[byte]):
If I fuzz this by providing random bytes, am I likely to detect a subtle issue with underflow, or detect the Pentium FOOF bug? Or imagine a C parser: fuzzing random bytes wouldn't trigger much of the parser. Without a lot of probes, it seems hard to test these function spaces!
My hunch is that this works due to a combination of factors:
- I chose a simple library to work with. Zopfli isn't trivial, but you aren't juggling a lot of state, for example.
- Fuzzers are good at probing the input space. If you compile with the right arguments the fuzzer will try to choose inputs which trigger different branches. You can even give good examples (a corpus) to start the fuzzer off. I didn't do this for my experiments, but its easy to imagine an LLM generating a decent starting corpus.
- Most code doesn't express subtle logic paths. If I test if a million inputs are correctly sorted, I've probably implemented the sorter correctly.
- Complex logic, when it exists, is broken up across functions. Our individual tests make it easier to ensure the combined calls work.
- The LLM produces correct code most of the time! The fuzz test is just there to validate we did the right thing.
Caveats, or don't try this at home
While the overall system seems to work, its far from ready to drop in to a new project.
The resulting Rust code is very "C-like"
By construction, we use the same unsafe C interface for each symbol we port. This is different from Syzygy, which generates a safe Rust version of the program in one shot. This was convenient but not strictly required: I could have tweaked the prompts and clearly indicate public/private interfaces, letting the LLM use more idiomatic Rust for internal functions. Retaining the same interfaces simplified writing the fuzz tests and let the LLM call into the original C code when debugging.
That said, because our end result has end-to-end fuzz tests and tests for every symbol, its now much easier to "rustify" the code with confidence. This is a great task for future work.
The automation isn't complete
I tweaked the agent framework and prompts as I went to get better results out of Gemini. I needed to have Claude come in at the end to finish the last few symbols, and I fixed a few typos here and there. With better prompting and a better agent framework, this intervention would be reduced, but likely not go away entirely.
Zopfli is easy
Zopfli is a simple library with many functions which are input/output oriented. It's not clear how this would work if you introduced more stateful interfaces.
Conclusions and future work
Whew. This ended up taking a few days and being more than the initial trivial experiment I intended. That said, I think there's some interesting insights:
- Porting via LLMs is surprisingly cost effective and only getting cheaper. Even with my multiple rounds of experimentation and tweaking agents etc, the total cost for this experiment was ~$50, or about $0.01 a line. (For comparison, Syzygy cost ~$1500 using the O3 model). I suspect this could be brought down another 10x by walking up a "complexity tree": first try porting symbols mechanically (constants, structs, enums), then trying out a cheap model before falling back to more expensive models. For instance, Gemini Flash 2.5 is capable of producing correct Rust code for some non-trivial problems.
- Full automation is hard. The chat based interface of LLMs/agents can lead us to believe that they are more capable than they really are. We don't often realize how much we're guiding the direction of the LLMs until we try to go completely hands off.
- Full automation isn't necessary. Imagine a system where you have agents port as many symbols as they possibly can, in parallel. If a symbol fails to port, you mark it "tainted" and move on. You then continue until you can't port anything else. In such a system, a human could be brought in to fix issues as they emerge, but you could still rely on the agents to handle >90% of the work of porting in an asynchronous manner.
If you're interested in the (truly terrible) code I used for the porting, you can find it on Github. I'm not sure if I'll continue down this route further myself, but let me know if you're interested in this space or trying to port a project and I'm happy to chat more!
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0







