





























My 2.5 year old laptop can write Space Invaders in JavaScript now (GLM-4.5 Air)
My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
29th July 2025
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
The models are pretty big—the smaller GLM-4.5 Air model is still 106 billion total parameters, which is 205.78GB on Hugging Face.
Ivan Fioravanti built this 44GB 3bit quantized version for MLX, specifically sized so people with 64GB machines could have a chance of running it. I tried it out... and it works extremely well.
I fed it the following prompt:
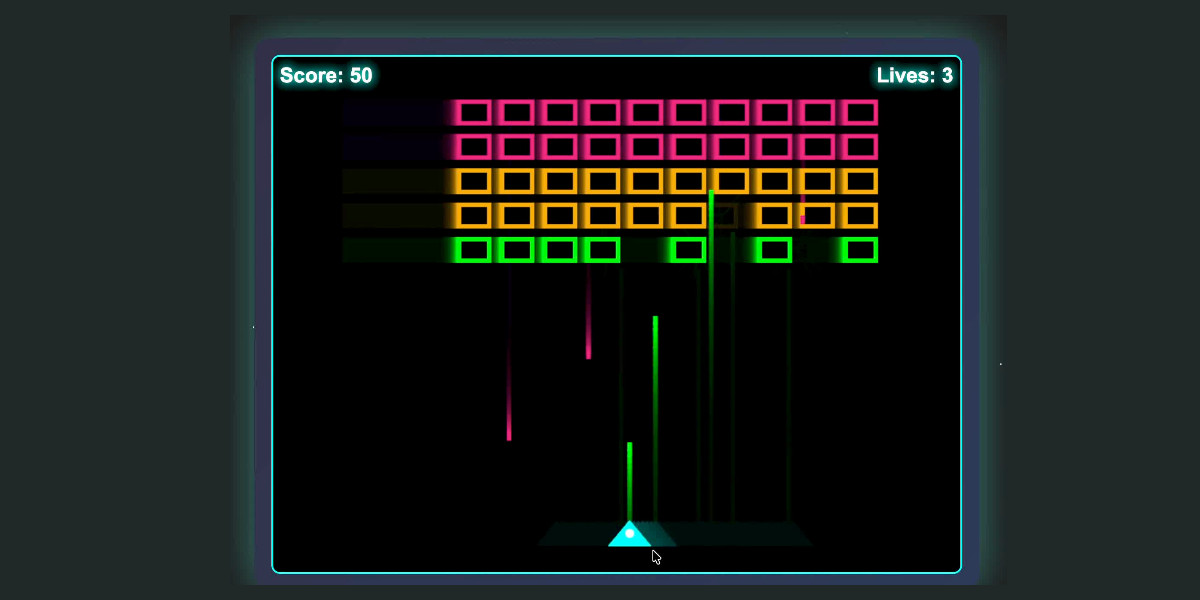
Write an HTML and JavaScript page implementing space invaders
And it churned away for a while and produced the following:
Clearly this isn’t a particularly novel example, but I still think it’s noteworthy that a model running on my 2.5 year old laptop (a 64GB MacBook Pro M2) is able to produce code like this—especially code that worked first time with no further edits needed.
How I ran the model
I had to run it using the current main branch of the mlx-lm library (to ensure I had this commit adding glm4_moe support). I ran that using uv like this:
uv run \
--with 'https://github.com/ml-explore/mlx-lm/archive/489e63376b963ac02b3b7223f778dbecc164716b.zip' \
pythonThen in that Python interpreter I used the standard recipe for running MLX models:
from mlx_lm import load, generate model, tokenizer = load("mlx-community/GLM-4.5-Air-3bit")
That downloaded 44GB of model weights to my ~/.cache/huggingface/hub/models--mlx-community--GLM-4.5-Air-3bit folder.
Then:
prompt = "Write an HTML and JavaScript page implementing space invaders" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) response = generate( model, tokenizer, prompt=prompt, verbose=True, max_tokens=8192 )
The response started like this:
The user wants me to create a Space Invaders game using HTML, CSS, and JavaScript. I need to create a complete, functional game with the following features:
- Player spaceship that can move left/right and shoot
- Enemy invaders that move in formation and shoot back
- Score tracking
- Lives/health system
- Game over conditions [...]
Followed by the HTML and this debugging output:
Prompt: 14 tokens, 14.095 tokens-per-sec
Generation: 4193 tokens, 25.564 tokens-per-sec
Peak memory: 47.687 GB
You can see the full transcript here, or view the source on GitHub, or try it out in your browser.
A pelican for good measure
I ran my pelican benchmark against the full sized models yesterday, but I couldn’t resist trying it against this smaller 3bit model. Here’s what I got for "Generate an SVG of a pelican riding a bicycle":

Here’s the transcript for that.
In both cases the model used around 48GB of RAM at peak, leaving me with just 16GB for everything else—I had to quit quite a few apps in order to get the model to run but the speed was pretty good once it got going.
Local coding models are really good now
It’s interesting how almost every model released in 2025 has specifically targeting coding. That focus has clearly been paying off: these coding models are getting really good now.
Two years ago when I first tried LLaMA I never dreamed that the same laptop I was using then would one day be able to run models with capabilities as strong as what I’m seeing from GLM 4.5 Air—and Mistral 3.2 Small, and Gemma 3, and Qwen 3, and a host of other high quality models that have emerged over the past six months.
More recent articles
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0








