Here’s an overview of how you use embeddings and how they work.
It’s geared towards technical writers who are learning about
embeddings for the first time.
Someone asks you to “make some embeddings”. What do you input? You input
text.1 You don’t need to provide the same amount of text every time.
E.g. sometimes your input is a single paragraph while at other times it’s
a few sections, an entire document, or even multiple documents.
What do you get back? If you provide a single word as the
input, the output will be an array of numbers like this:
[-0.02387, -0.0353, 0.0456]
Now suppose your input is an entire set of documents. The output
turns into this:
[0.0451, -0.0154, 0.0020]
One input was drastically smaller than the other, yet they both produced
an array of 3 numbers. Curiouser and curiouser. (When you work with real embeddings,
the arrays will have hundreds or thousands of numbers, not 3. More on that
later.)
Here’s the first key insight. Because we always get back the same amount of
numbers no matter how big or small the input text, we now have a way to
mathematically compare any two pieces of arbitrary text to each other.
But what do those numbers MEAN?
1 Some embedding models are “multimodal”, meaning you can also provide images, videos,
and audio as input. This post focuses on text since that’s the medium that we
work with the most as technical writers.
Haven’t seen a multimodal model support taste, touch, or smell yet!
The size of the array depends on what model you’re using. Gemini’s
text-embedding-004 model returns an array of 768 numbers whereas Voyage AI’s
voyage-3 model returns an array of 1024 numbers. This is one of the reasons
why you can’t use embeddings from different providers interchangeably. (The
main reason is that the numbers from one model mean something completely
different than the numbers from another model.)
I don’t know. After the model has been created (trained), I’m pretty sure that
generating embeddings is much less computationally intensive than generating
text. But it also seems to be the case that embedding models are trained in
similar ways as text generation models2, with all the energy usage
that implies. I’ll update this section when I find out more.
2 From You Should Probably Pay Attention to Tokenizers: “Embeddings
are byproduct of transformer training and are actually trained on the heaps of
tokenized texts. It gets better: embeddings are what is actually fed as the
input to LLMs when we ask it to generate text.”
Ideally, your embedding model can accept a huge amount of input text,
so that you can generate embeddings for complete pages. If you try to
provide more input than a model can handle, you usually get an error.
As of October 2024 voyage-3 seems to the clear winner in terms of
input size3:
For my particular use cases as a technical writer, large input size is an
important factor. However, your use cases may not need large input size, or
there may be other factors that are more important. See the Massive Text Embedding Benchmark
(MTEB) leaderboard.
3 These input limits are based on tokens, and each service calculates
tokens differently, so don’t put too much weight into these exact numbers. E.g.
a token for one model may be approximately 3 characters, whereas for another one
it may be approximately 4 characters.
4 Previously, I incorrectly listed this model’s input limit as 3072. Sorry
for the mistake.
Back to the big mystery. What the hell do these numbers MEAN?!?!?!
Let’s begin by thinking about coordinates on a map.
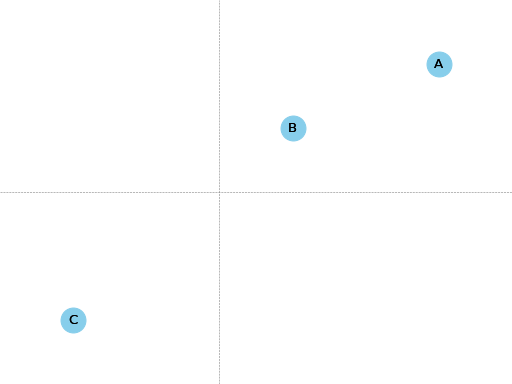
Suppose I give you three points and their coordinates:
Point
X-Coordinate
Y-Coordinate
A
3
2
B
1
1
C
-2
-2
There are 2 dimensions to this map: the X-Coordinate and the
Y-Coordinate. Each point lives at the intersection of an X-Coordinate
and a Y-Coordinate.
Is A closer to B or C?
A is much closer to B.
Here’s the mental leap. Embeddings are similar to points on a map.
Each number in the embedding array is a dimension, similar to the
X-Coordinates and Y-Coordinates from earlier. When an embedding
model sends you back an array of 1000 numbers, it’s telling you the
point where that text semantically lives in its 1000-dimension space,
relative to all other texts. When we compare the distance between two
embeddings in this 1000-dimension space, what we’re really doing is
figuring out how semantically close or far apart those two texts are
from each other.
The concept of positioning items in a multi-dimensional
space like this, where related items are clustered near each other,
goes by the wonderful name of latent space.
The most famous example of the weird utility of this technology comes from
the Word2vec paper, the foundational research that kickstarted interest
in embeddings 11 years ago. In the paper they shared this anecdote:
Starting with the embedding for king, subtract the embedding for man,
then add the embedding for woman. When you look around this vicinity of the
latent space, you find the embedding for queen nearby. In other words,
embeddings can represent semantic relationships in ways that feel intuitive
to us humans. If you asked a human “what’s the female equivalent
of a king?” that human would probably answer “queen”, the same answer we get from embeddings. For more explanation of the underlying theories, see Distributional semantics.
The 2D map analogy was a nice stepping stone for building intuition but now we need
to cast it aside, because embeddings operate in hundreds or thousands
of dimensions. It’s impossible for us lowly 3-dimensional creatures to
visualize what “distance” looks like in 1000 dimensions. Also, we don’t know
what each dimension represents, hence the section heading “Very weird
multi-dimensional space”.5 One dimension might represent something
close to color. The king-man+woman≈queen anecdote suggests that these
models contain a dimension with some notion of gender. And so on.
Well Dude, we just don’t know.
The mechanics of converting text into very weird multi-dimensional space are
complex, as you might imagine. They are teaching machines to LEARN, after all.
The Illustrated Word2vec is a good way to start your journey down that
rabbithole.
After you’ve generated your embeddings, you’ll need some kind of “database”
to keep track of what text each embedding is associated to. In the experiment
discussed later, I got by with just a local JSON file:




![Africa CEO Forum : énergie, IA, routes… les paris du continent [Business Africa]](http://static.euronews.com/articles/stories/09/27/46/96/640x360_cmsv2_01295edd-3441-5908-8c4e-adb7e75b9f71-9274696.jpg?1746786054#)


























 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










