

:max_bytes(150000):strip_icc()/20250722-MEATRESTINGUPDATE-Butter-basting-steak-fish-liz-clayman-d9afb24942da4cde9850708f230400f6.jpg)



























Reverse engineering GitHub Actions cache to make it fast
Before this work began, we already had a faster alternative to Github Actions cache. Our approach was different: we forked each of the popular first-party actions that depended on Actions cache to point to our faster, colocated cache. But my coworkers weren’t satisfied with that solution, since it required users to change a single line of code.
Apart from the user experience, maintaining these forks steadily turned into a nightmare for us. We kept at it for a while, but eventually reached an inflection point, and the operational cost became too high.
So, I set out to reverse engineer GitHub Actions cache itself, with one goal: make it fast. Really fast. And this time, without having to maintain forks or requiring the user to change a single line of code. Not one.
Sniffing out GitHub cache requests
The first step was fully understanding the inner workings of the GitHub Actions cache. Our prior experience forking the existing cache actions proved helpful, but earlier this year, GitHub threw us a curveball by deprecating its legacy cache actions in favor of a new Twirp-based service using the Azure Blob Storage SDK. Although a complete redesign, it was a win in our eyes — we love Protobufs. They’re easy to reason about, and once we could reverse engineer the interface, we could spin up a fully compatible, blazing-fast alternative.
Enter our new friend: Claude. (It’s 2025, after all.) After a few iterations of creative prompt engineering, we sniffed out the requests GitHub made to its control plane and came up with a proto definition of the actions service. If you’re hacking on similar black boxes, I highly recommend trusting an LLM with this.
But what about the Azure Blob Storage? The GitHub system switched to Azure, but our cache backend runs atop a self-hosted MinIO cluster, which is an S3-compatible blob storage. In an ideal world, all blob stores would be interchangeable, but we do not live in an ideal world (at least, not yet). We had to figure out the shape of those requests. It took a little more effort to figure it out, but in the end, all roads led to network proxies.
Proxy here, proxy there, proxy everywhere
Achieving a truly seamless experience with zero required code changes requires some magic: every VM request still appears to go to the original destination (i.e. GitHub’s control plane and Azure Blob Storage), but under the hood, we sneakily redirect them within the network stack.
Now, a little color on the context: Blacksmith is a high-performance, multi-tenant CI cloud for GitHub Actions. Our fleet runs on bare-metal servers equipped with high single-core performance gaming CPUs and NVMe drives. At the time of writing this, we manage 500+ hosts across several data centers globally, spinning up ephemeral Firecracker VMs for each customer’s CI job. Every job runs Ubuntu with GitHub-provided root filesystems.
With the context set, let’s talk implementation. 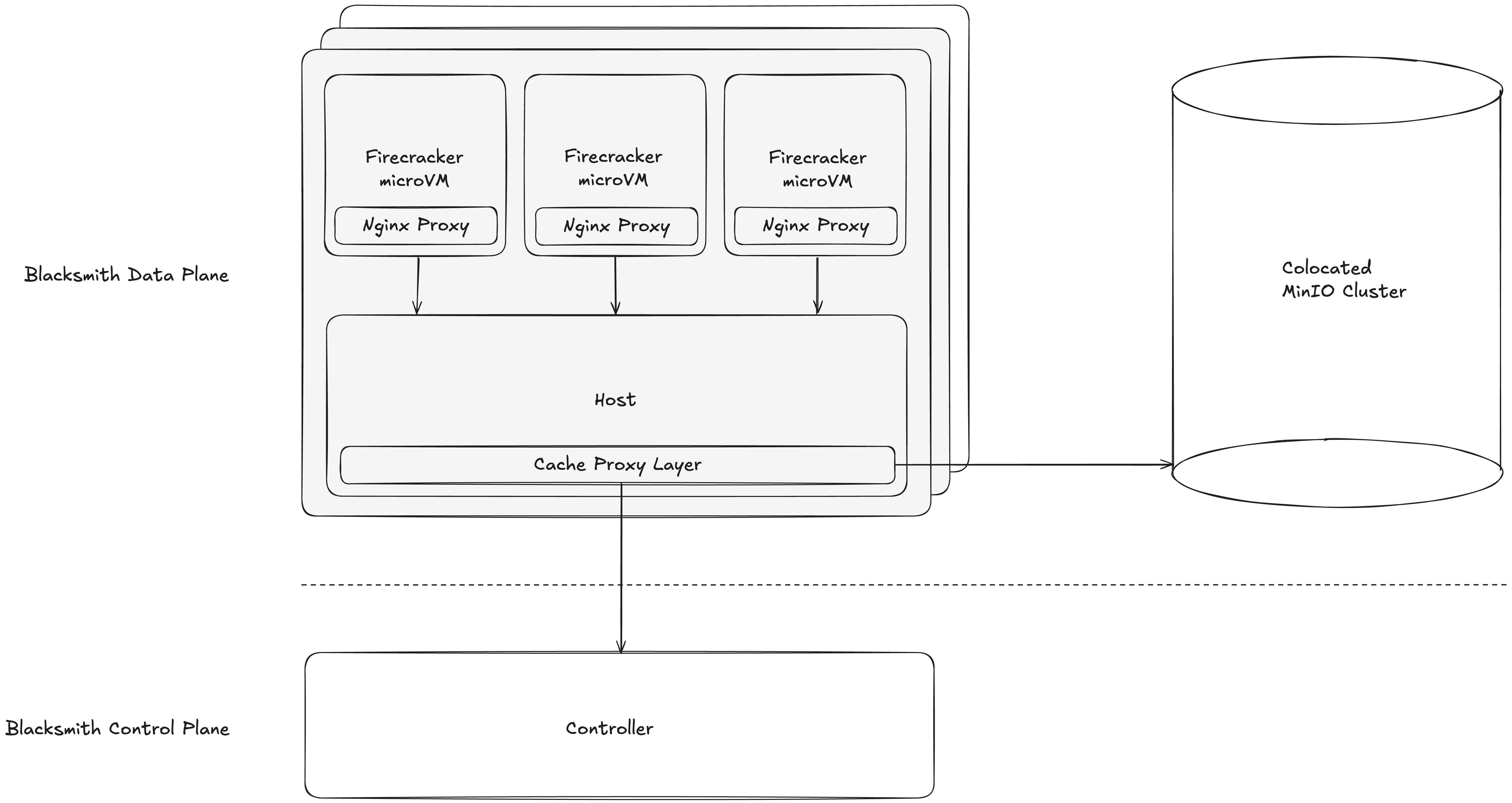
VM proxy
Inside each VM, we configured a lightweight NGINX server to proxy requests back to our host-level proxy. Why this extra layer? It’s simple: we need to maintain state for every upload and download, and access control is non-negotiable. By handling proxying inside the VM, we pick up a nice bonus: jobs running inside Docker containers can have their egress traffic cleanly intercepted and routed through our NGINX proxy. No special hacks required.
These proxy servers are smart about what they forward. Cache-related requests are all redirected to our host proxy, while other GitHub control plane requests — such as those we don’t handle, like GitHub artifact store — go straight to their usual destinations.
The choice of NGINX came down to practicality. All our root file systems ship with NGINX preinstalled, and the proxying we do here is dead simple. Sometimes the best tool is the one that’s already in the box, and in this case, there was no need to look any further.
Fighting the Azure SDK
While NGINX takes care of request routing for the GitHub Actions control plane, getting things to play nicely with the Azure SDK called for some serious kernel-level network gymnastics.
We were several cycles deep into our implementation when a surprising reality emerged: our new caching service was lagging behind our legacy version, particularly when it came to downloads. Curious, we drove back into the source code of GitHub toolkit. What we found was telling: if the hostname isn’t recognized as an Azure Blob Storage (e.g., blob.core.windows.net), the toolkit quietly skips many of its concurrency optimizations. Suddenly, the bottleneck made sense.
To address this, we performed some careful surgery. We built our own Azure-like URLs, then a decoder and translator in our host proxy to convert them into S3-compatible endpoints. Only then did the pieces fall into place, and performance once again became a nonissue.
We started with VM-level DNS remapping to map the Azure-like URL to our VM agent host. But redirecting just these specific requests to our host-level proxy required an additional step to get there. Our initial implementation at this proxying layer leaned on iptables rules to steer the right traffic toward our host proxy. It worked, at least until it didn’t. Through testing, we quickly hit the limits: iptables was already doing heavy lifting for other subsystems inside our environment, and with each VM adding or removing its own set of rules, things got messy fast, and extremely flakey.
That led us to nftables, the new standard for packet filtering on Linux, and a perfect fit for our use case:
- Custom rule tables: Namespacing rules per VM became simple, making it straightforward to add or remove these rules.
- Atomic configuration changes: Unlike iptables, nftables allows us to atomically swap out entire config blocks. This avoids conflicts with multiple readers and writers.
Once we had every relevant request flowing through our host-level proxy, we built our own in-house SDK to handle two-way proxying between Azure Blob Storage and AWS S3. Throughput — for uploads and downloads — is a big deal to us, so keeping our proxy lightweight as possible was non-negotiable. We relied on some handy Go primitives to make that happen: the standard io library makes streaming buffers painless, letting us pass an io.Reader cleanly from one request to another and skip any unnecessary data buffering. For the HTTP client, we went with Resty, which excels at connection pooling. This proves useful because all requests from the host are routed to MinIO. And when you have multiple VMs in play, each uploading and downloading dozens of concurrent data streams to the object store, this becomes absolutely critical.
Sometimes, failing is the faster option
Caching is an interesting engineering concept where failing to retrieve a cache is better than trying to do so in a degraded network environment where things slow down to a crawl. In a distributed system like ours, the chances of sporadic network degradation are non-zero and the best thing in those cases is to simply have a cache miss – rebuilding the cached objects is better than taking 10 minutes to retrieve them.
Interestingly, that same mindset towards failure held true throughout our development process as well. All of this proxying magic demands a ton of testing, just to make sure we support all official GitHub and popular third-party cache actions. You can plan for weeks, but the ecosystem is always ready to surprise you. Most of the time, engineers in these scenarios strive for correctness first. But sometimes, embracing failure is actually the faster, better option.
This system was a perfect example of that lesson. As soon as we launched the beta, we started seeing some actions that depended on slightly different caching semantics than GitHub’s own. Some expected serialized Protobufs; others wanted those Protobufs converted back to JSON. Every mismatch mattered, and the only way to uncover them all was by getting real-world failures at scale during our beta — there was no substitute.
Colocated cache is king
What was the outcome of all of this effort? Simply put, we’ve seen real world customer workflows running on Blacksmith now enjoy cache speeds up to 10x faster and multiples higher throughout than those on GitHub Actions, with zero code changes required in the workflow files themselves.
Before:
2025-06-04T19:06:33.0291949Z Cache hit for: node-cache-Linux-x64-npm-209c07512dcf821c36be17e1dae8f429dfa41454d777fa0fd1004d1b6bd393a8
2025-06-04T18:26:33.3930117Z Received 37748736 of 119159702 (31.7%), 35.9 MBs/sec
2025-06-04T18:26:34.3935922Z Received 114965398 of 119159702 (96.5%), 54.7 MBs/sec
2025-06-04T18:26:34.6696155Z Received 119159702 of 119159702 (100.0%), 49.8 MBs/sec
2025-06-04T18:26:34.6697118Z Cache Size: ~114 MB (119159702 B)After:
2025-06-04T19:06:33.0291949Z Cache hit for: node-cache-Linux-x64-npm-209c07512dcf821c36be17e1dae8f429dfa41454d777fa0fd1004d1b6bd393a8
2025-06-04T19:06:33.4272115Z Received 119151940 of 119151940 (100.0%), 327.5 MBs/sec
2025-06-04T19:06:33.4272612Z Cache Size: ~114 MB (119151940 B)
In this case, it was so fast that it only consumed 1 log line to show that it had completed right away!
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










