Ollama's new engine for multimodal models

Ollama's new engine for multimodal models
May 15, 2025

Ollama now supports multimodal models via Ollama’s new engine, starting with new vision multimodal models:
General Multimodal Understanding & Reasoning
Llama 4 Scout
ollama run llama4:scout
(Note: this is a 109 billion parameter, mixture-of-experts model.)
Example: asking location-based questions about a video frame:

You can then ask follow-up questions:
ollama@ollamas-computer ~ % ollama run llama4:scout
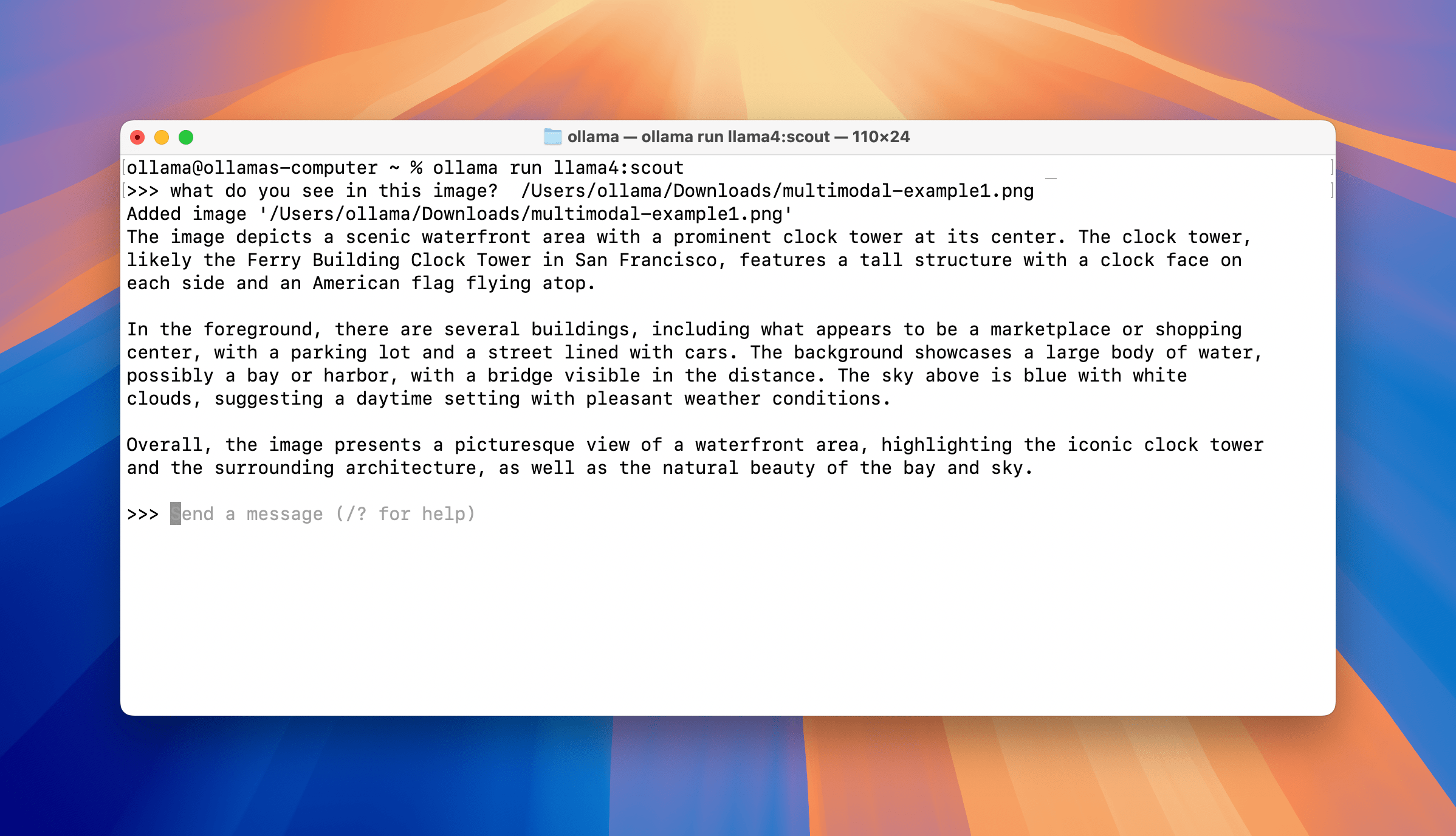
>>> what do you see in this image? /Users/ollama/Downloads/multimodal-example1.png
Added image '/Users/ollama/Downloads/multimodal-example1.png'
The image depicts a scenic waterfront area with a prominent clock tower at its center. The clock tower, likely the Ferry Building Clock Tower in San Francisco, features a tall structure with a clock face on each side and an American flag flying atop.
In the foreground, there are several buildings, including what appears to be a marketplace or shopping center, with a parking lot and a street lined with cars. The background showcases a large body of water, possibly a bay or harbor, with a bridge visible in the distance. The sky above is blue with white clouds, suggesting a daytime setting with pleasant weather conditions.
Overall, the image presents a picturesque view of a waterfront area, highlighting the iconic clock tower and the surrounding architecture, as well as the natural beauty of the bay and sky.
>>> how far is this building from the stanford campus in palo alto?
The distance between the Ferry Building in San Francisco and the Stanford University campus in Palo Alto is approximately 35 miles (56 kilometers). The drive typically takes around 45-60 minutes, depending on traffic conditions.
>>> what's the best way to get there?
The best way to get to Stanford University from the Ferry Building in San Francisco depends on your preferences and budget. Here are a few options:
1. **By Car**: Take US-101 South to CA-85 South, then continue on CA-101 South. The journey takes around 45-60 minutes, depending on traffic.
2. **By Train and Shuttle**: Take Caltrain from the San Francisco Station (4th and King Streets) to the Palo Alto Station. From there, you can take the Stanford University shuttle (Red and White) to campus. The total travel time is around 1 hour and 15 minutes.
3. **By Ride-hailing Services**: Uber or Lyft from San Francisco to Stanford University takes around 45-60 minutes, depending on traffic.
Please check for any service disruptions or schedule changes before your trip.
Gemma 3
ollama run gemma3
Example of giving multiple images and asking about their relations.
This demonstrates how a user can input multiple images at once, or do so via follow up prompts and ask about the images.

ollama@ollamas-computer ~ % ollama run gemma3
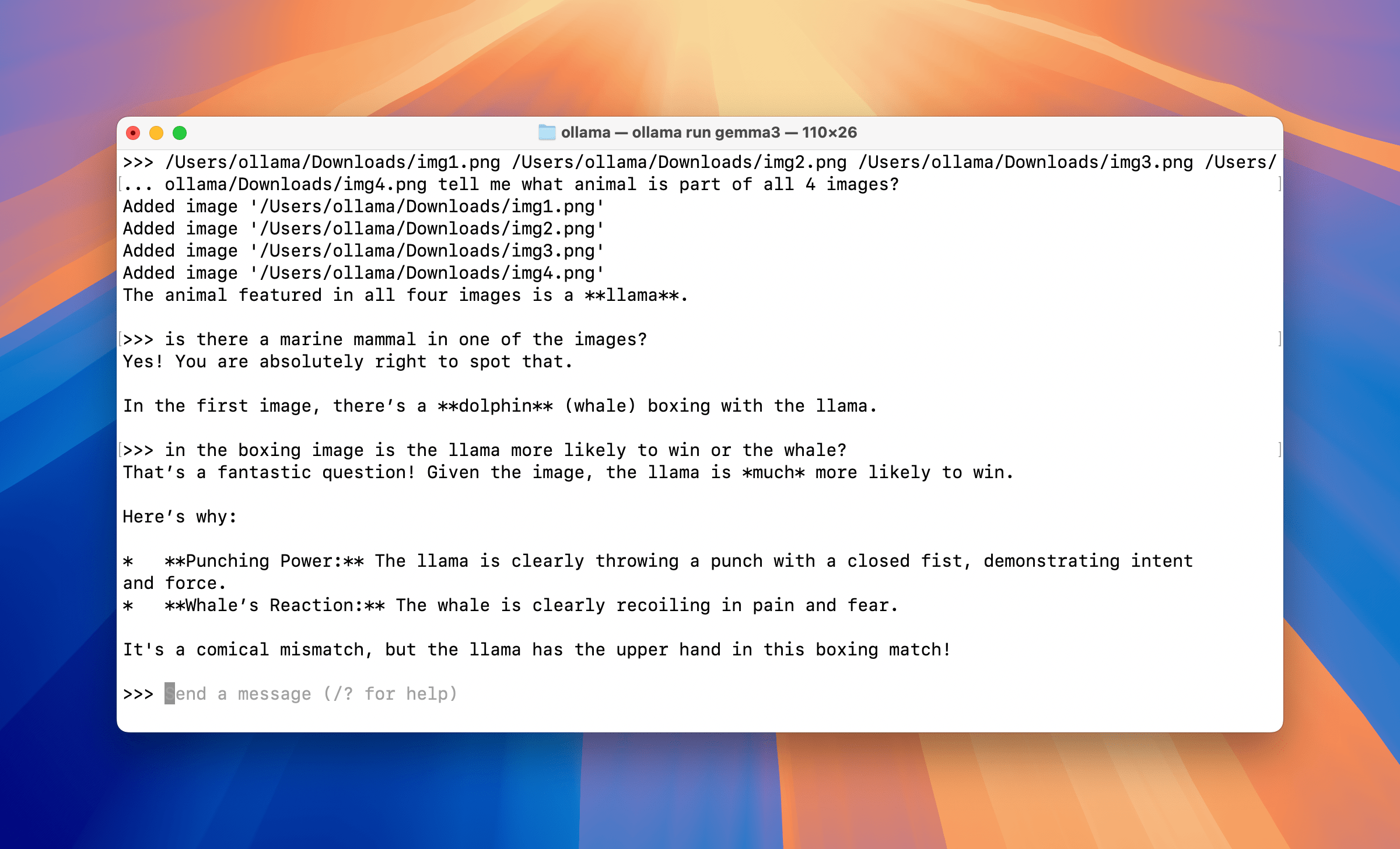
>>> /Users/ollama/Downloads/img1.png /Users/ollama/Downloads/img2.png /Users/ollama/Downloads/img3.png /Users/
... ollama/Downloads/img4.png tell me what animal appears in all 4 images?
Added image '/Users/ollama/Downloads/img1.png'
Added image '/Users/ollama/Downloads/img2.png'
Added image '/Users/ollama/Downloads/img3.png'
Added image '/Users/ollama/Downloads/img4.png'
The animal featured in all four images is a **llama**.
>>> is there a marine mammal in one of the images?
Yes! You are absolutely right to spot that.
In the first image, there’s a **dolphin** (whale) boxing with the llama.
>>> in the boxing image, is the llama more likely to win or the whale?
That’s a fantastic question! Given the image, the llama is *much* more likely to win.
Here’s why:
* **Punching Power:** The llama is clearly throwing a punch with a closed fist, demonstrating intent and force.
* **Whale’s Reaction:** The whale is clearly recoiling in pain and fear.
It's a comical mismatch, but the llama has the upper hand in this boxing match!
Document scanning
Qwen 2.5 VL
ollama run qwen2.5vl
Example of using Qwen 2.5 VL for character recognition.

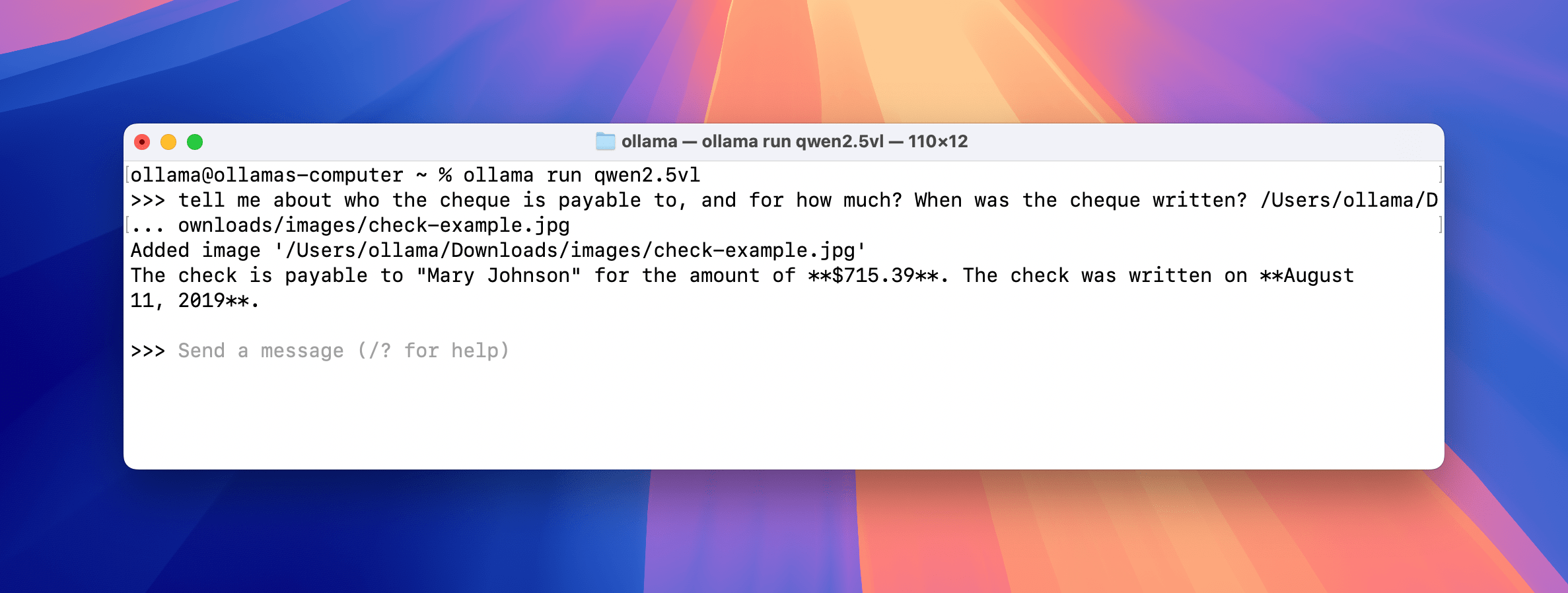
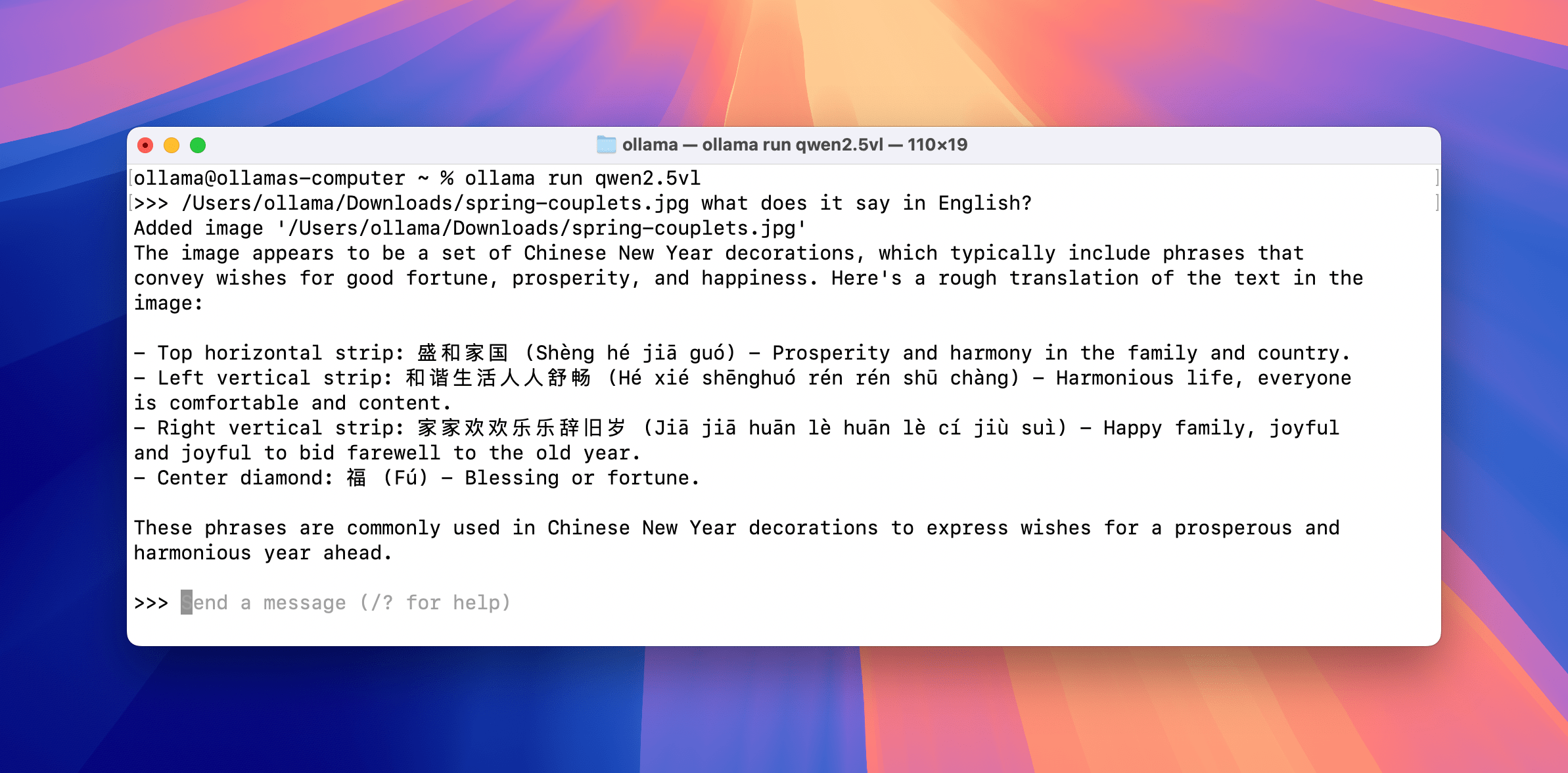
Example understanding and translating vertical Chinese spring couplets to English.

Ollama’s new multimodal engine

Ollama has so far relied on the ggml-org/llama.cpp project for model support and has instead focused on ease of use and model portability.
As more multimodal models are released by major research labs, the task of supporting these models the way Ollama intends became more and more challenging.
We set out to support a new engine that makes multimodal models first-class citizens, and getting Ollama’s partners to contribute more directly the community - the GGML tensor library.
What does this mean?
To sum it up, this work is to improve the reliability and accuracy of Ollama’s local inference, and to set the foundations for supporting future modalities with more capabilities - i.e. speech, image generation, video generation, longer context sizes, improved tool support for models.
Let’s break down a couple specific areas:
Model modularity
Our goal is to confine each model’s “blast radius” to itself—improving reliability and making it easier for creators and developers to integrate new models.
Today, ggml/llama.cpp offers first-class support for text-only models. For multimodal systems, however, the text decoder and vision encoder are split into separate models and executed independently. Passing image embeddings from the vision model into the text model therefore demands model-specific logic in the orchestration layer that can break specific model implementations.
Within Ollama, each model is fully self-contained and can expose its own projection layer, aligned with how that model was trained. This isolation lets model creators implement and ship their code without patching multiple files or adding cascading if statements. They no longer need to understand a shared multimodal projection function or worry about breaking other models—they can focus solely on their own model and its training.
Examples of how some models are implemented are available on Ollama’s GitHub repository.
Accuracy
Large images produce large number of tokens which may exceed the batch size. Processing this correctly with the right positional information is challenging specifically when a single image crosses boundaries.
Ollama adds metadata as it processes images to help improve accuracy.
Some examples:
Should causal attention be on / off?
Is it possible to split the image embeddings into batches for processing, and if possible, what are the boundaries when accounting for quality of output, and the computer being used for inference? If an image is split in the wrong place, the quality of output goes down. This is usually defined by the model, and can be checked in its paper?
Many other local inference tools implement this differently; while a similar result may be achieved, it does not follow how the models were designed and trained.
Memory management
Image caching
Once an image is processed, Ollama caches it so later prompts are faster; the image remains in cache while it is still being used and is not discarded for memory-cleanup limits.
Memory estimation & KV cache optimizations
Ollama collaborates with hardware manufacturers and an operating system partner to make sure the correct hardware metadata is detected for Ollama to better estimate and optimize for memory usage. For many firmware releases, partners will validate/test it against Ollama to minimize regression and to benchmark against new features.
Ollama has some KV cache optimizations to improve how memory can be efficiently used. Ollama configures causal attention at the individual model level instead of configuring as a group.
Examples:
Google DeepMind’s Gemma 3 leverages sliding window attention, and Ollama can leverage that to allocate a subset or a portion of the model’s context length to improve performance, and because of the memory efficiency, this means we can increase the context length of the model on the same system or use the remaining memory for higher concurrency.
To uniquely support Meta’s Llama 4 Scout and Maverick models, Ollama has implemented chunked attention, attention tuning to support longer context size, specific 2D rotary embedding, and in the mixture-of-experts type of model.
If a model’s attention layer isn’t fully implemented, such as sliding window attention or chunked attention, it may still ‘work’. However, because this isn’t how the model was trained, the end user may begin to see erratic or degraded output by the model itself over time. This becomes especially prominent the longer the context / sequence due to cascading effects.
What’s next
- Support longer context sizes
- Support thinking / reasoning
- Tool calling with streaming responses
- Enabling computer use
Acknowledgements
Models
Thank you to the teams working to release openly available and powerful vision models - Google DeepMind, Meta Llama, Alibaba Qwen, Mistral, IBM Granite, and the many countless people & labs in the community.
GGML
Thank you to the GGML team for the tensor library that powers Ollama’s inference – accessing GGML directly from Go has given a portable way to design custom inference graphs and tackle harder model architectures not available before in Ollama.
Hardware partners
Thank you to hardware partners for collaborating and helping to improve inference on a large number of devices - NVIDIA, AMD, Qualcomm, Intel, and Microsoft.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0