















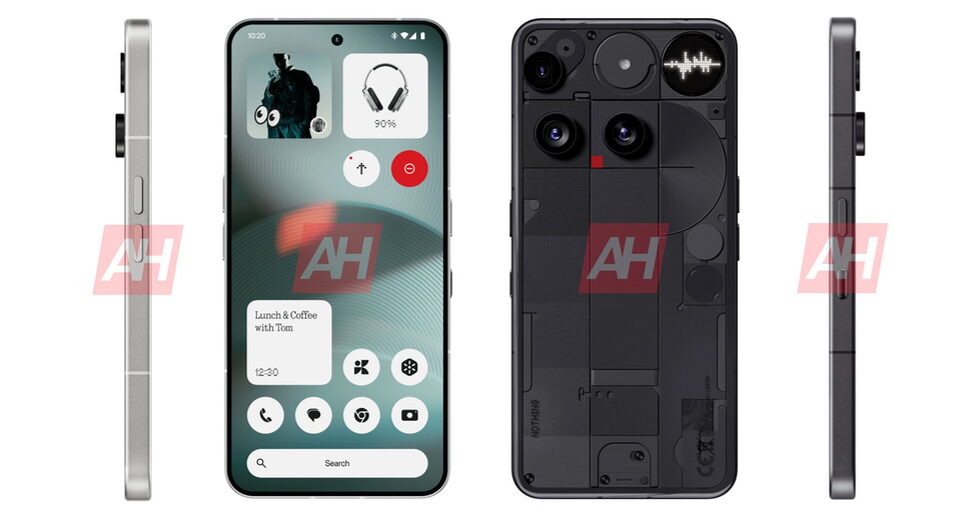













Lossless LLM 3x Throughput Increase by LMCache

Redis for LLMs - Infinite and Ultra-Fast
LMCache is an LLM serving engine extension to reduce TTFT and increase throughput, especially under long-context scenarios. By storing the KV caches of reusable texts across various locations, including (GPU, CPU DRAM, Local Disk), LMCache reuses the KV caches of any reused text (not necessarily prefix) in any serving engine instance. Thus, LMCache saves precious GPU cycles and reduces user response delay.
By combining LMCache with vLLM, LMCache achieves 3-10x delay savings and GPU cycle reduction in many LLM use cases, including multi-round QA and RAG.
Try LMCache with pre-built vllm docker images here.
🚀 Performance snapshot

💻 Installation and Quickstart
Please refer to our detailed documentation for LMCache V1 and LMCache V0
Interested in Connecting?
Fill out the interest form, sign up for our newsletter, or drop an email, and our team will reach out to you!
🛣️ News and Milestones
- High performance CPU KVCache offloading
- Disaggregated prefill
- P2P KVCache sharing
- vLLM production stack ecosystem
📖 Blogs and documentations
Our latest blog posts and the documentation pages are available online
Community meeting
The community meeting for LMCache is hosted weekly. Meeting Details:
-
Tuesdays at 9:00 AM PT – Add to Calendar
-
Tuesdays at 6:30 PM PT – Add to Calendar
Meetings alternate weekly between the two times. All are welcome to join!
Contributing
We welcome and value any contributions and collaborations. Please check out CONTRIBUTING.md for how to get involved.
Citation
If you use LMCache for your research, please cite our papers:
@inproceedings{liu2024cachegen,
title={Cachegen: Kv cache compression and streaming for fast large language model serving},
author={Liu, Yuhan and Li, Hanchen and Cheng, Yihua and Ray, Siddhant and Huang, Yuyang and Zhang, Qizheng and Du, Kuntai and Yao, Jiayi and Lu, Shan and Ananthanarayanan, Ganesh and others},
booktitle={Proceedings of the ACM SIGCOMM 2024 Conference},
pages={38--56},
year={2024}
}
@article{cheng2024large,
title={Do Large Language Models Need a Content Delivery Network?},
author={Cheng, Yihua and Du, Kuntai and Yao, Jiayi and Jiang, Junchen},
journal={arXiv preprint arXiv:2409.13761},
year={2024}
}
@article{yao2024cacheblend,
title={CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion},
author={Yao, Jiayi and Li, Hanchen and Liu, Yuhan and Ray, Siddhant and Cheng, Yihua and Zhang, Qizheng and Du, Kuntai and Lu, Shan and Jiang, Junchen},
journal={arXiv preprint arXiv:2405.16444},
year={2024}
}
License
This project is licensed under Apache License 2.0. See the LICENSE file for details.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










