





























Everything You Need to Know About Grok 4

You might have already heard about the release of Grok 4, the latest breakthrough from Elon Musk’s xAI team.
In this post, we'll do a deep dive into what this model is, its stats, whether it is any good or just another regular AI model, if it achieves AGI, and overall community impressions so far.
By the end of this post, you'll have all the information you need to decide whether you want to use Grok 4 or not.
Without any further ado, let's jump in!
Grok 4 is a reasoning model and the most intelligent model so far, as you can see in the benchmark below. To be honest, this model not only competes with other AI models but also with humans, making it the first of its kind (we'll discuss this shortly).
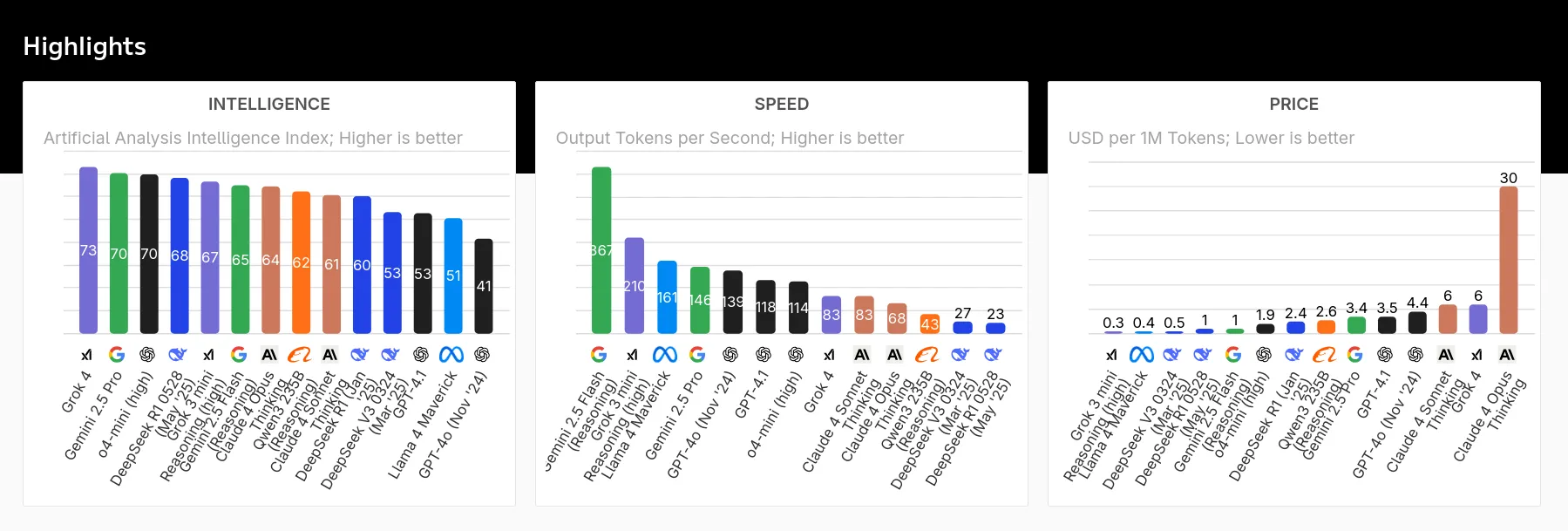
As shown in the chart above, it has excellent scores in Intelligence, Speed, and Pricing compared to recent AI models. It ranks at the top of the artificial intelligence chart, but if we look closely, it's a bit slower in generating responses. Grok 4 has about 13.58 seconds of latency (Time to First Token), which measures the time to receive the first part of the response from an AI model. This is just below the OpenAI o4-mini-high and equal to the Claude Sonnet 4 model.
It has 100 times more training data than Grok 2, which is the first public AI model by xAI, and approximately 10 times more reinforcement learning compute than any other AI model available in the market right now.

It comes with a 256k token context window (the amount of information the model can read and remember at once), which is quite low compared to the recent Gemini 2.5 Pro with a 1M token context window. It's just a bit ahead of the Claude 4 lineup, which has about 200k tokens.
Grok 4 pricing is pretty standard, but comes with a catch. It's the same as the pricing for Grok 3 at $3 per million input tokens (doubles after 128k) and $15 per million output tokens (doubles after 128k).
-
This model scores an all-time high in GPQA Diamond with 88%, which is a big win over the 86% from Gemini 2.5 Pro.
(GPQA Diamond tests the model’s ability to answer graduate-level, expert-domain questions (e.g., physics, law, medicine))
-
It achieves an all-time high score in the Humanity Last Exam with 24%, beating Gemini 2.5 Pro's previous score of 21%.
(Humanity Last Exam tests the capabilities of large language models (LLMs) at the frontier of human knowledge)
-
It has the joint highest score for MMLU-Pro and AIME 2024 at 87% and 94%, respectively.
(MMLU-Pro tests the model across 57+ professional-level subjects, including law, engineering, medicine, and more. AIME 2024 measures the model's performance on high school olympiad-level math problems)
-
It also crushes the coding benchmarks, ranking #1 in the LiveCodeBench with 79.4%, where the second best is 74.2%.
(LiveCodeBench is a real-time coding benchmark that tests models in live, interactive programming tasks and not just in static code generation)
Yeah, there are a few other benchmarks where it leads all the models, but these are pretty much the most interesting ones.

So, all in all, currently, if you take any benchmarks, most likely Grok 4 is leading all of them.
But how do you access it? It's available via both API and a paid subscription. You can access it on SuperGrok for $30/month or $300/year, which gives you access to standard Grok 4. However, to access Grok 4 Heavy, you need to subscribe to the SuperGrok Heavy plan, which costs $300/month or $3000/year.
- Grok 4: This is the standard generalist model fine-tuned for a range of tasks like problem-solving, general conversation, and writing. It's the default that comes in the Grok 4 lineup.
- Grok 4 Heavy: This is the specialized version in the Grok 4 lineup. It uses multi-agents, i.e., runs several AI agents in parallel to analyze and solve a problem and come up with the best solution. This really helps with accuracy and is mainly built for heavy research, data analysis, and basically anything that requires extensive thinking.

Even better, if you just want to test the models, it's also available on OpenRouter, so if you have an API key, you're good to go.
If you're not sure what AGI (Artificial General Intelligence) is, let me give you a brief idea. Basically, Generative AI, which we use, like the OpenAI models, Claude Sonnet models, and others, generates content based on learned patterns or what they've been trained on.
However, AGI generates content consciously, with creativity comparable to human intelligence.
And let me tell you, my friend, this is not something you can build out of nowhere just like that, no. Here we're talking about reaching an artificial intelligence equivalent to the human brain, and that's not easily achieved.
Now, back to the topic, it has not yet achieved AGI, but it is one leap forward in the race to AGI and the first model to cross the 15% score in the ARC-AGI benchmark, all at a lower cost.

xAI also tested Grok 4 in a real-world simulation called Vending Bench. Basically, in this benchmark, the idea is to see whether a model can manage a small business over time and handle everything that comes with it, like restocking inventory, working with suppliers, adjusting prices, and more. This is a very interesting benchmark to test an AI model in a real-world scenario, and it did a pretty good job at it.

As you can see, Grok 4 is generating more than twice the revenue and scale compared to the top competitor, Claude Opus 4.
There's no comparison between Grok 4 and the other AI models here, and it's doing it all at a lower price. So yeah, this is a great step toward AGI, but it's simply not there yet.
Musk himself has claimed that you can copy and paste your entire source code into a query, and it will fix bugs or add features for you, just like that. It's also claimed to work "better than Cursor".

And again, that seems to be true enough. The community is building a lot of stuff with this model since it was released less than a week ago, and the results we're getting are insane.
It literally one-shotted something that crazy, and if that's not enough, it's literally said to be better than PhD levels in every subject. Let that sink in.
🗣️ "With respect to academic questions, Grok 4 is better than PhD levels in every subject. No exceptions." - Elon Musk
On the release of this model, they gave a quick idea of what to expect next from xAI, and here's what that looks like:

We're expected to see the following in the coming months:
- Grok code - release next month
- Grok multi-modal, or browsing agent release in September
- Grok Video generation in late October
So, if your main purpose with an AI model is coding, it might be worth waiting one more month to see if that's even better for your use case.
Grok 4 has about 99% accuracy in picking the right tools and making tool calls with proper arguments almost every single time.
It's designed to be agentic, which means that with single or multiple agents working behind the scenes, it can easily handle multiple tasks. It's an academic wizard, as you can see in the benchmarks we've discussed above, and one of the first AI models to break the 10% barrier in the ARC-AGI benchmark, which enables it to make decisive decisions and plans, making it a very capable model.
However, when it comes to multi-modal capabilities, especially with image generation and analysis, it's not much better and performs poorer than the top multi-modal capabilities AI models like o3, Claude 4, etc. Although this will significantly improve in the coming days.
Another thing I really hate about this model is the rate limit that's implemented on top of xAI. Almost every 2-3 continuous prompts, you get rate limited for a few minutes, and that's really frustrating, especially considering that you'd be using this model in a more research-based situation where you'll likely be making multiple prompts to the model to get the answer you expect.
If I have to summarize everything we've read so far, it's definitely the best model available for reasoning, heavy research, and data analysis (at least for now!). Grok 4 is not really meant for coding, so it’s better to wait one more month for a coding-tuned model.
This one's definitely the biggest breakthrough in the AI world so far, with the claim that it's supposedly the closest model to reach AGI so far. So yeah, there's definitely a lot of potential in this model, so use it with caution.
With great power comes great responsibility! 😉
Let me know what you think of Grok 4 so far, and if you've tested it yourself, how it performed. Let me know in the comments below!
We've recently added support for Grok 4 on Forge. If this sounds interesting to you, you'll definitely want to try it on Forge. You can create an account and get started in just a minute. See for yourself if it performs as well as the benchmarks suggest and if you’d like to add this model to your daily workflow.
1. Artificial Analysis. “Grok 4 Model Card.” https://artificialanalysis.ai/models/grok-4 ↩
2. OpenRouter. “OpenRouter: Access LLMs via a Unified API.” https://openrouter.ai ↩
3. xAI. “Grok 4 Launch & Benchmarks Livestream.” Twitter/X Post. https://x.com/xai/status/1943158495588815072 ↩
4. Andon Labs. “Vending Bench: A Real-World AGI Simulation.” https://andonlabs.com ↩
5. Grok. “Subscribe to Grok and SuperGrok Plans.” https://grok.com/#subscribe ↩
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0










